News
Anthropic overtakes OpenAI in API revenue
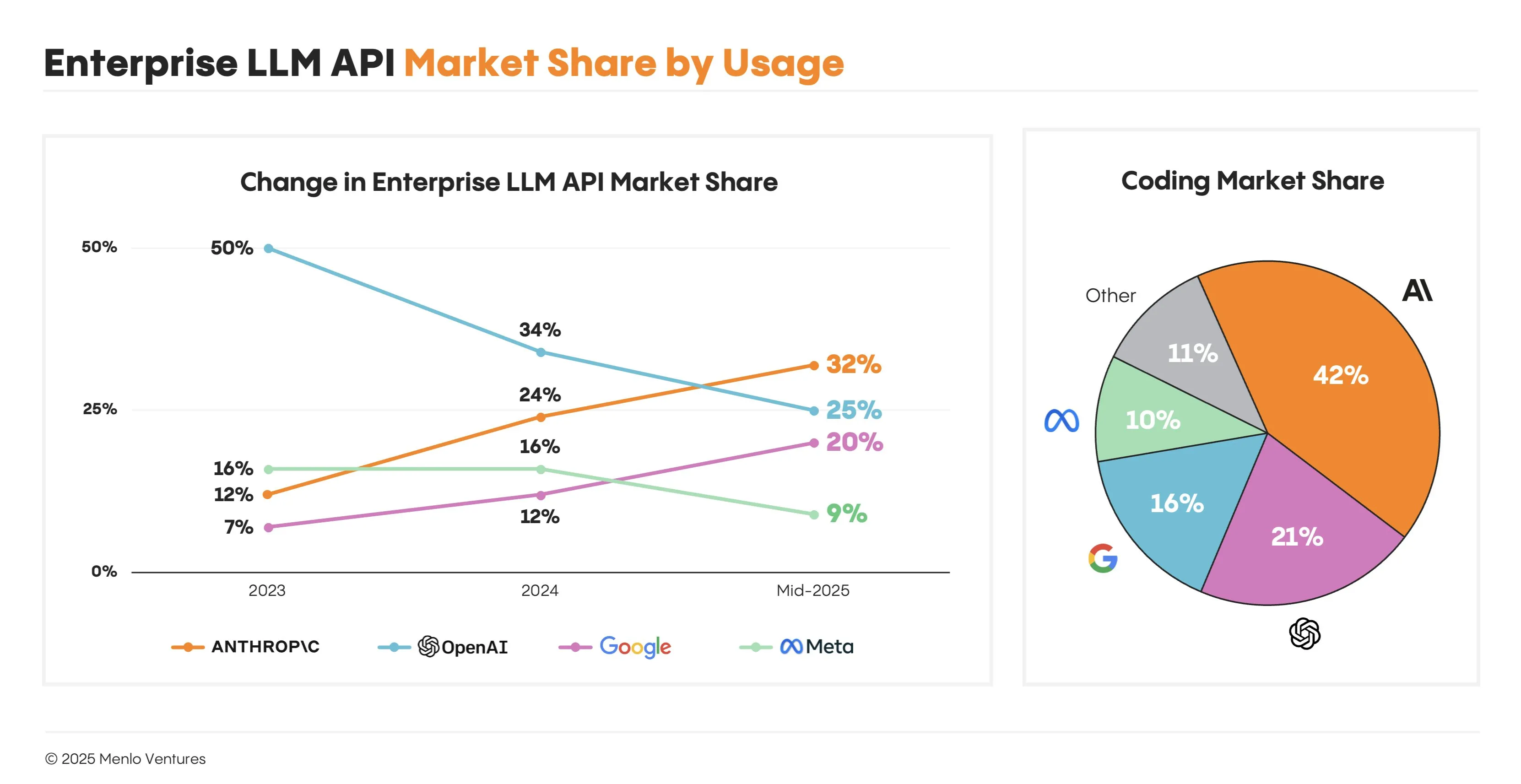
A recent report from Menlo Ventures has shown that Anthropic has recently passed OpenAI in terms of LLM API revenue, capturing over 30% of the market versus OpenAI’s 25%. They also have an even more commanding lead for coding market share capturing 42% of the market. This comes of the heels of the explosion in usage of Cursor and Claude Code in the last year, as Anthropic has become the defacto standard for real world agentic applications.
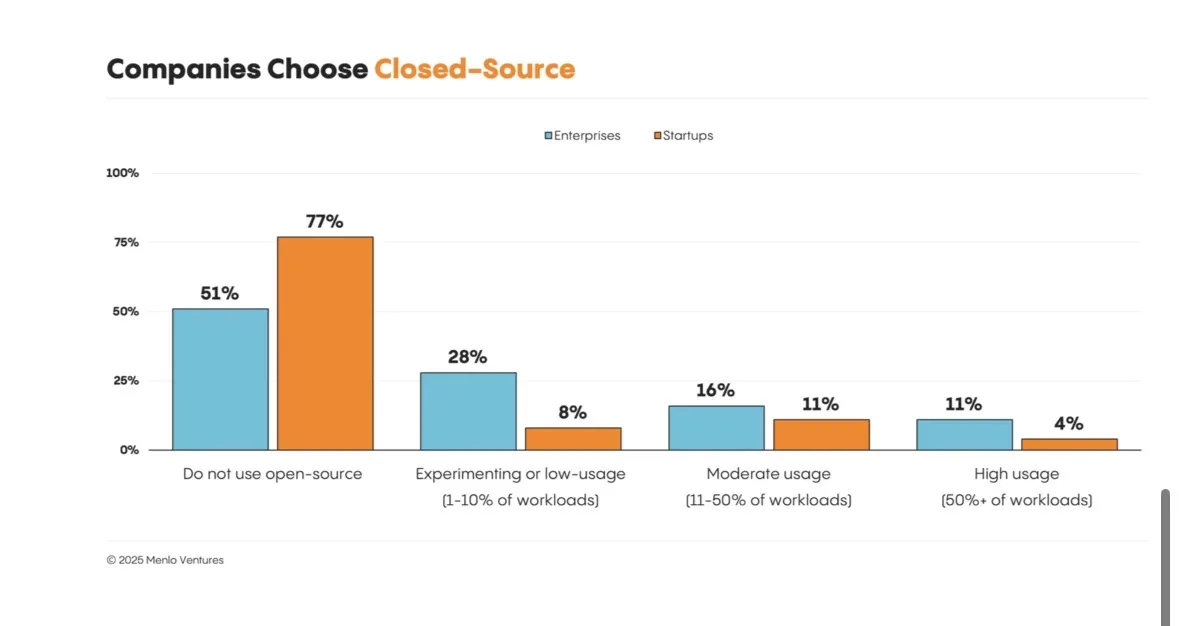
Also, as a part of the report, they showed that only 11% of enterprises are using open-source models in high-usage scenarios, and about 50% of them are not using open-source models at all, even for experimentation or smaller tasks. This is due to the high costs of running or finetuning your own model versus optimizing a system prompt for a closed source model, especially with the top models changing every week. I expect this number to go up in the future if AI progress starts to stagnate, or go to 0 if someone achieves AGI.
Releases
Z.ai takes over the top
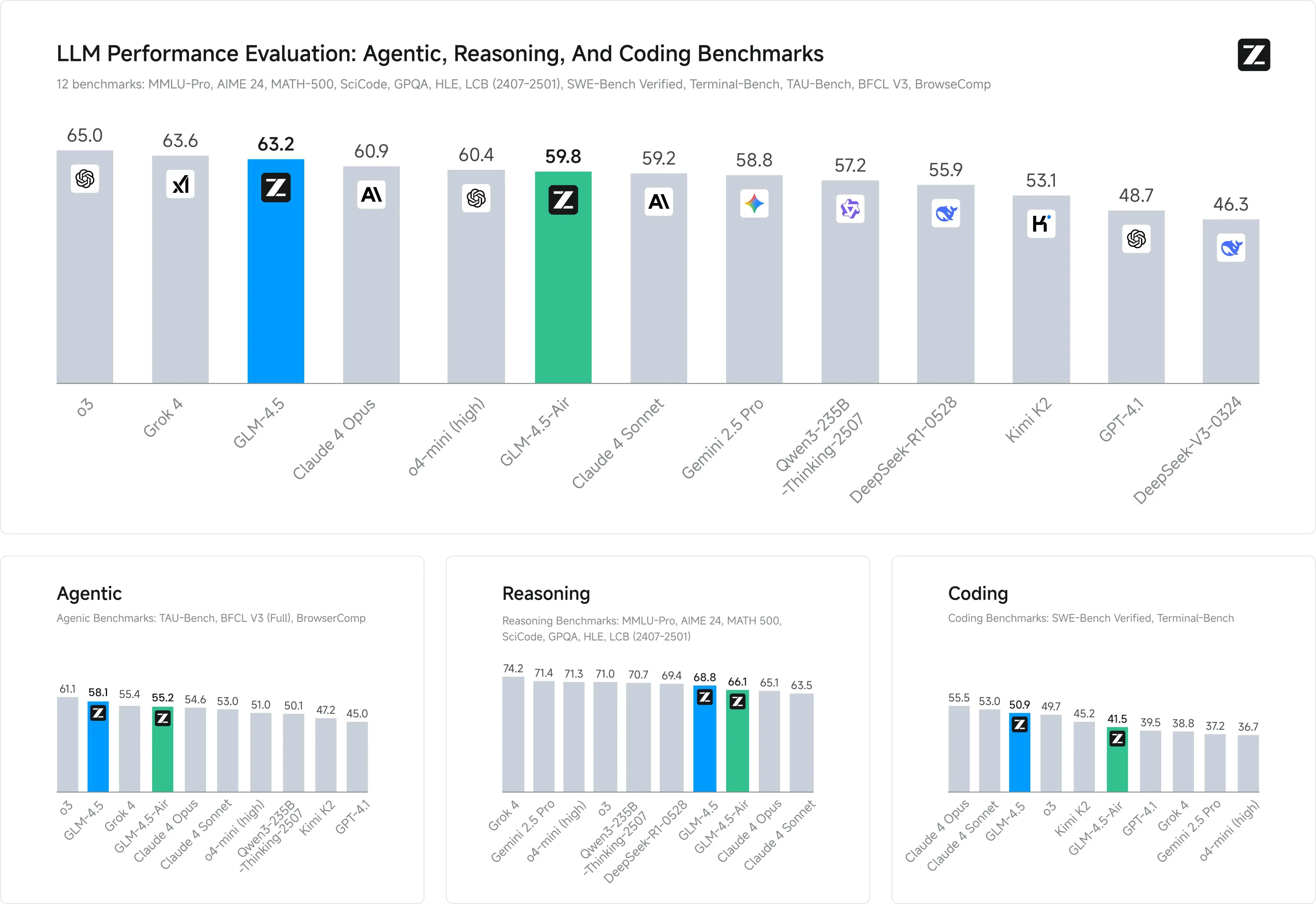
I have been hyping up Z.ai the last few weeks now, and they have not disappointed. This week they have released their GLM 4.5 series of models, which from what I have seen, are the best open source agentic models on the market right now.
They have released 2 variants, 4.5 and 4.5 Air. They are both MoE models, with 4.5 having 355 billion total params and 32 billion active params, and Air having 106 billion params with 12 billion active. What this means is that 4.5 needs a proper multi gpu (H100s or better) setup to run at any meaningful speeds, while the Air model could feasible be run at home with a combo cpu + gpu setup using something like Ktransformers.
But why would you want to use these models? Simply put, because they are incredible.
Public benchmarks are one thing, but do they actually pass the test in the real world? Of course they do.
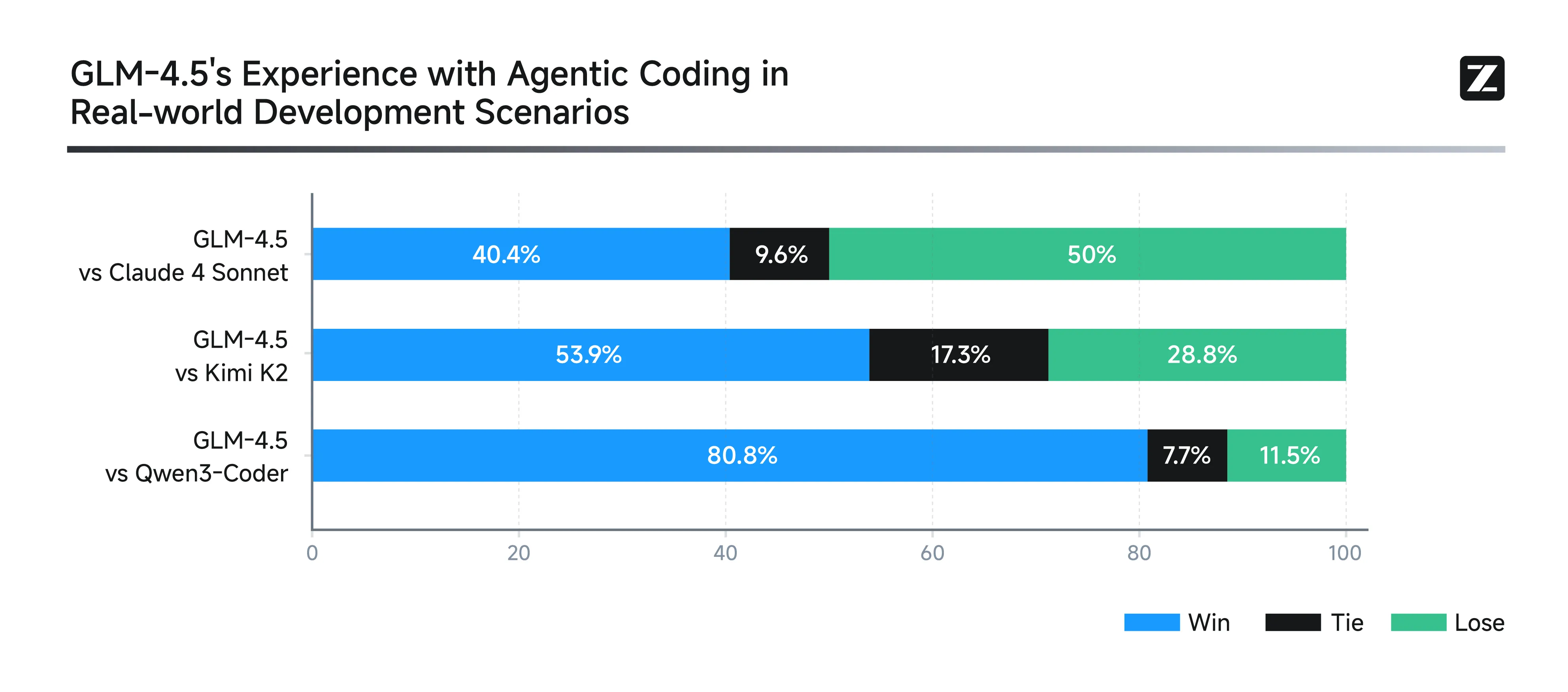
You don’t have to take other people’s word for it though. I have switched to using GLM 4.5 in Claude Code, and I have noticed no practical difference, other than the cost being 5x less. Reddit also agrees, with users comparing the Air model to the new Qwen3 235B model that was released last week, while being 2x smaller, and others also agreeing with me that the large model is akin to Sonnet/Opus for agentic and coding tasks.
I plan on running the Air model as my daily driver local model, probably taking the role that I use o3 for for day to day tasks. I will also probably stay with the large 4.5 models as well for my coding workflows as well for the foreseeable future.
If you haven’t been able to tell already, these models blow the previous best models of Kimi K2 and Qwen3 by a hefty amount, all while being smaller and faster than them.
You can try both of the models for free right now on z.ai.
Wan 2.2
Alibaba has improved their SOTA open source video model, Wan 2.1, releasing their Wan 2.2 series of models. There are 2 models that they released, a 5 billion parameter “standard” model that can do both text and image to video, and then also 2 MoE models with 28 billion params with 14B active, one for text to video and the other for image to video.
The MoE models are interesting as they have 2 experts, one for high noise denoising for the early part of the generation process, and another for low noise denoising later for later steps. I think this will end up being similar to the SDXL refiner, where the community finds a way to get rid of it and unify the model to not need as many steps and parameters to make it work just as well.
From what I have seen so far, the models work well, definitely not sota when compared to closed source models like Veo3, but still a very big bump in quality versus the previous best, Wan 2.1.
A pink sports car is driving very fast along a beach at sunset, the car says “REPLICATE” on the side, it drifts around in the sand - From fofr on Twitter
Qwen3-30B-3A Update
Qwen released 3 models last week, and they must have really enjoyed all the attention that brought them, because they did the same this week, dropping 3 new versions of their 30B3A MoE Qwen3 model.
The first 2 are the basic reasoning and non reasoning variants, both of which are comparable to Gemini 2.5 Flash.
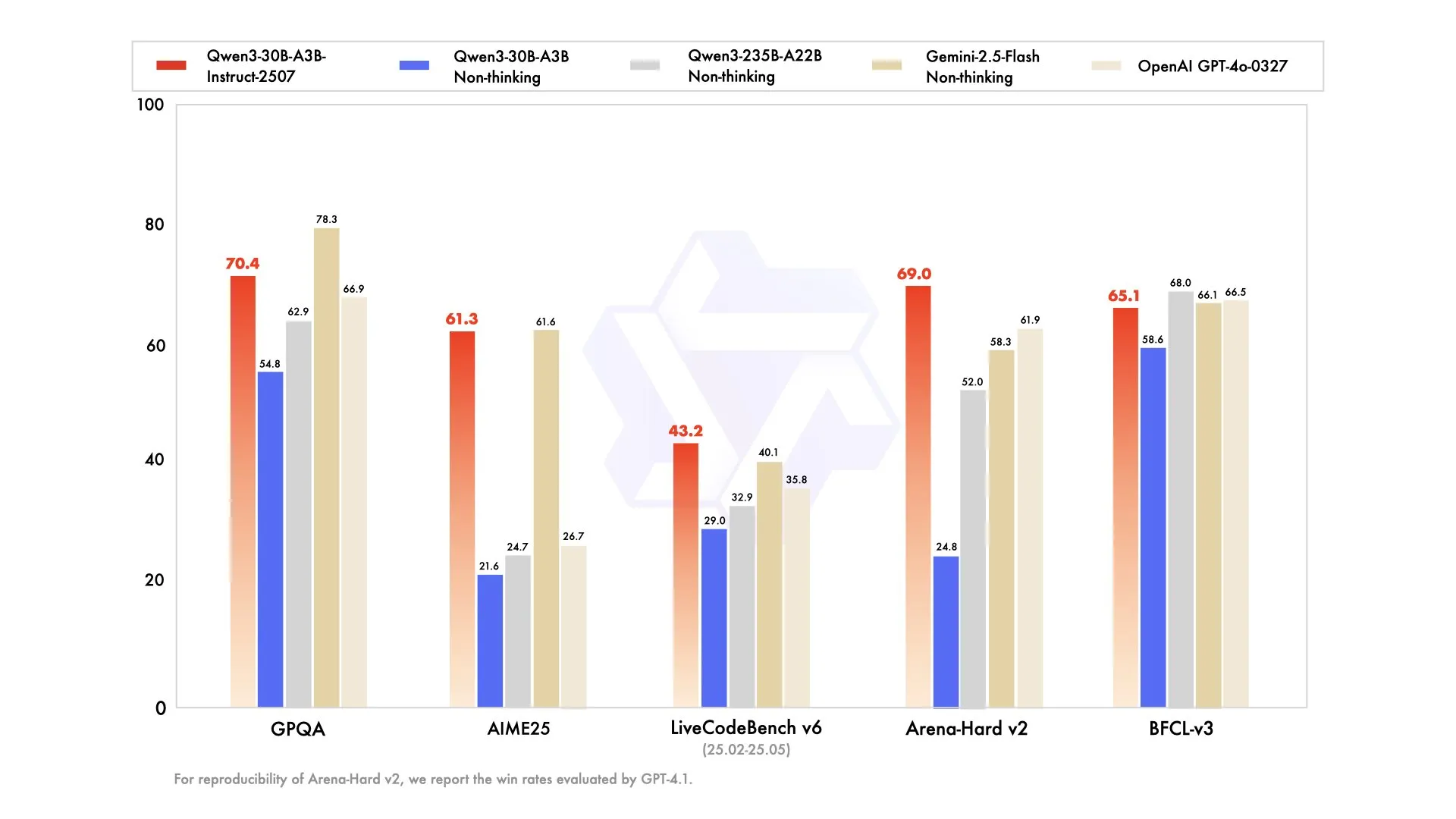
The 3rd model they released in the series is a agentic coding model, which, while not being that impressive when compared GLM 4.5 and Sonnet, does have the distinction of being the first “small” open source model that is capable of doing agentic coding at all, a task which has eluded open source for a while.
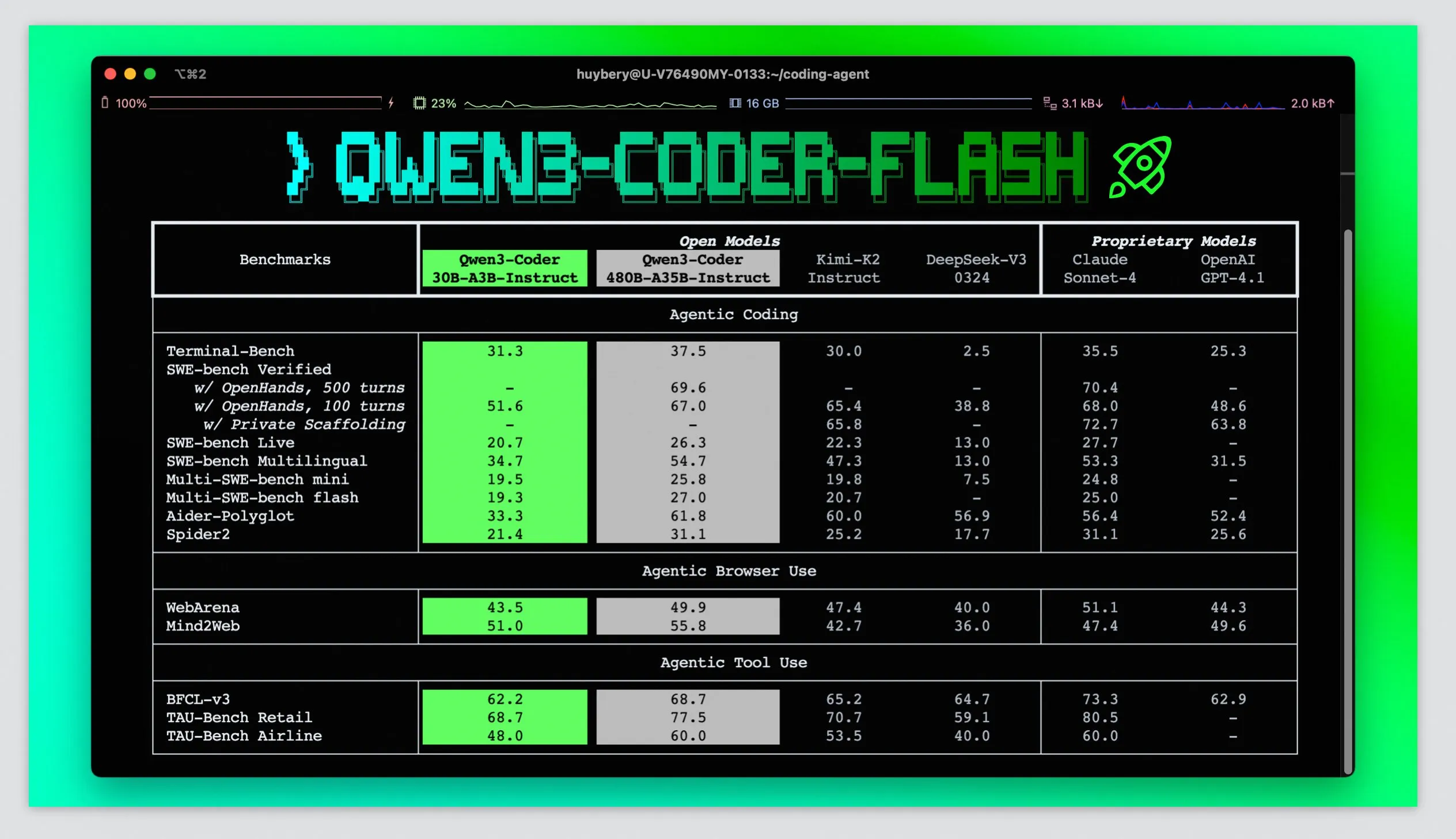
These models are interesting and exciting because they can be run at relatively high speeds (> 40 tokens per second) on computers without GPUs, giving more people access to these models without breaking the bank.
New BFL Open Source Model
Black Forest Labs has partnered with Krea to make a new open source image generation model, called Flux Krea dev. The model is focused on getting rid of the AI feel that many image generators have, and also allowing for unique aesthetics similar to Midjourney. They have also focused on having exceptional realism and image quality. The model uses the same architecture as the original Flux dev model, making it compatible with all image generation frameworks out of the box.

Speed Round
Useful tools or topics I found this week that may or not be AI related, but I didn’t have time to write a full section about.
Cerebras Code
Cerebras is launching their own Claude Code model hosting competitor, offering the Qwen3 coder model for $50 a month while also being 20 times faster. Qwen3 coder, sadly, does not appear to be that great of an agentic coding model, especially when compared to the new GLM 4.5 model that just came out. If Cerebras starts offering the GLM 4.5 model, I will immediately be picking this up though, as the speeds are almost instantaneous for text generation.
Gemini Deep Think
Google has released an upgraded version of their Gemini 2.5 Pro model called Gemini 2.5 DeepThink, which is based on the model that recently got a gold medal at the International Math Olympiad. They have scaled up the test time compute by allowing Gemini to think for longer, and also in parallel, and then be able to select the best options after going and exploring a whole bunch of different choices that it could potentially go and make.
It benchmarks very well on both public and private evals, beating even the overfit Grok 4 model from XAi. If you would like to use it, it is available through Google’s AI-Ultra subscription tier. And they say it should come out on the Gemini API in the coming weeks.
ChatGPT study mode
OpenAI has released a study mode to use to learn new subjects.
Users quickly figured out that under the hood, it’s just a prompt, thus making OpenAI a ChatGPT wrapper. Also you can have study mode at home (or with any other LLM) just by copying their system prompt.
Trackio
Weights and Biases is the most used library for tracking machine learning experiments, and it is a buggy mess, but there have been no good alternatives that researchers could use. Until now. Our saviours at Huggingface have released a library called Trackio, which is an open source, local version of Weights and Biases that you can use to track your experiments. Its meant as a drop in replacement, so you shouldn’t need to update any of you logging code at all.
Just update your code to use import trackio as wandb and your project will be free of the hell that is W&B forever.
VibeKit Auth
Wouldn’t it be nice if people could use their ChatGPT or Claude Pro subscription in your app? Now you can, using a new library called VibeKit.
Claude Tokenizer Exploration
Claude’s tokenizer is weird, Sasuke_420 on Twitter breaks down how weird it really is.
MoE finetuning library
Finetuning mixture of experts models is notoriously hard, so team at Character AI have released a battle hardened trainer written in pure PyTorch to help the community more easily fine tune these models.
Use ChatGPT agent to find coupon codes
Thank me later, which you can do by subscribing to the newsletter (link below).
Finish
I hope you enjoyed the news this week. If you want to get the news every week, be sure to join our mailing list below.
Giraffes Volleyball Championship 2022 - from remi on twitter