News
Be careful who you get your inference from
It has been reported recently that different inference providers of gpt-oss provide endpoints with differing levels of quality. In a report released by Artificial Analysis this week, these reports have been formally verified, as they find that there is a >10% gap in benchmark scores depending on what provider you are using.
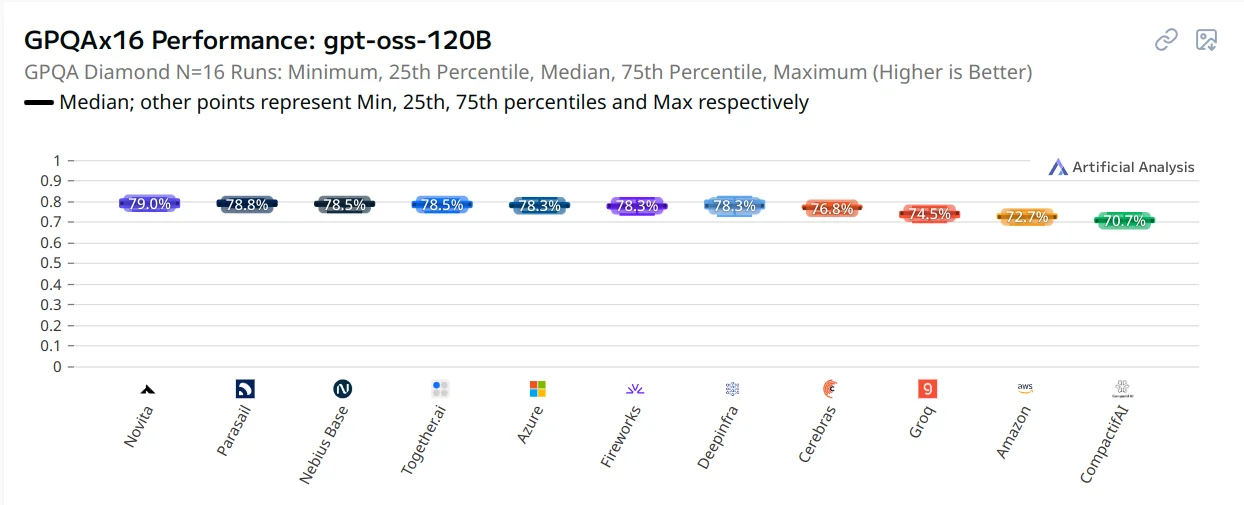
This report has caused some action, as previously Azure had been one of the worst available endpoints, but because of the report, they have updated their endpoint to serve the correct version. They say the issue was that the version of vLLM they were using did not respect the reasoning effort parameter, causing the model to be on medium reasoning effort instead of high.
This also highlights how important reasoning is for the new OpenAI models (gpt-oss and GPT5). Many users have been reporting that the difference between GPT5 and GPT5-high is night and day, with regular GPT5 being borderline unusable (for coding tasks) while GPT5-high works fairly well.
Claude 3.5 and 3.6 Deprecation
Anthropic recently announced that two of their most influential models, Claude Sonnet 3.5 and 3.6, are going to be deprecated in 2 months (October 22, 2025). These models are formative for Anthropic, as they started the death grip Anthropic has had on agentic coding models over the last year.
Sonnet 3.5 specifically is potentially the last “pure” LLM we will see for a while, that was tastefully trained and not benchmaxxed with an egregious amount of reinforcement learning.
This sudden deprivation has caught a lot of people off guard and has caused an outcry from many in the technical community, as these models have much more “soul” and “feeling” than the likes of GPT-4o, which also caused a lot of controversy when OpenAI announced they were getting rid of it last week, causing OpenAI to reinstate the model for the time being.
We will see if Anthropic sets up any “research” endpoints that users can access these models from still, similar to what the did for Opus 3. If not, I will miss the models, they were the first “good enough” agentic coders that could be used every day. Expect a funeral for these models similar to that of Sonnet 3.
Releases
GLM 4.5 Vision
The Z.ai team has released a new, multimodal variant of their text-exclusive LLM GLM 4.5. The new model, like the model it is built from, it is state of the art across all open source vision models. It is based on the smaller GLM 4.5 Air model, allowing it to feasibly be run at home.
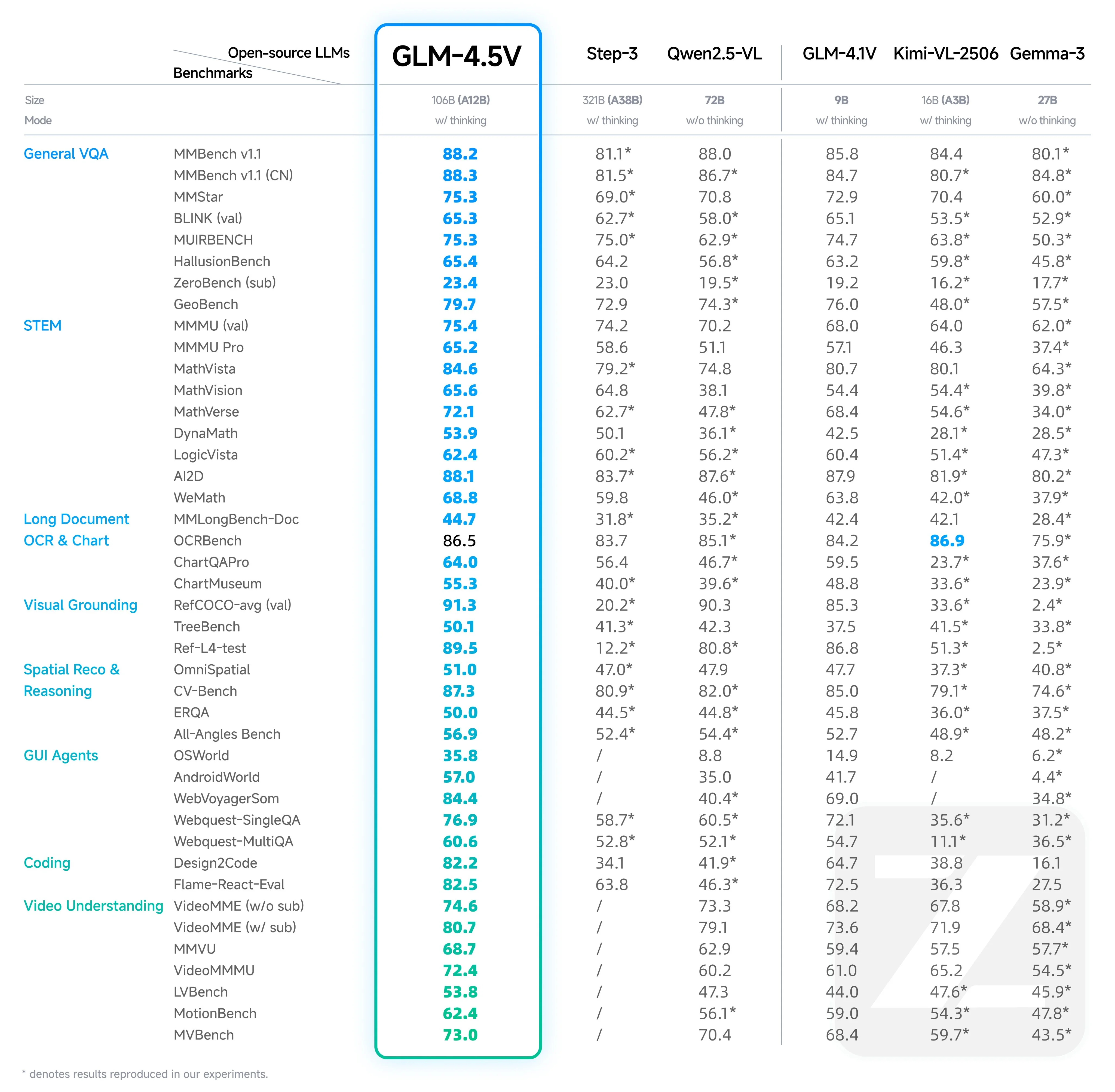
Despite the good benchmarks, it is a bit unpolished, as there have been numerous issues, including overthinking and output formatting. Z.ai has remedied some of them since the release, but other issues still persist. I would not recommend using the model at this point because of the above issues, and would instead use the GLM 4.1 model, which performs closely to the 4.5 model while being 9B params instead of 120B.
VLM’s in general are still rather lack luster in comparison to their text only brethren, as there are many, many instances of them exhibiting overfitting, bias, or behaviour that makes you think they cannot see anything at all, as highlighted by this research paper that came out this week.
Also along side this they also released research reports for the vision models (GLM 4.1 and 4.5) and also for the text based models. If you are a RL researcher, I would also go and check out their RL training framework SLIME, word on the street is that it is very nice to use.
DINO V3
Changing it up from the usual LLM and image generation models, Meta FAIR has released the latest in their DINO series of computer vision models.
These models are used for extracting features from images, so if you wanted to make an image dedupe model, a rare bird classifier, or make a custom segmentation model, DINO is the model to use. It excels in low data regimes, given its strong base understanding of images.

The model, unlike previous, has been scaled to billions of parameters, something which has previously been difficult for CV researchers to do. It also does very well on high resolution images, and has set new SOTA on pretty much every CV benchmark it can be applied to.
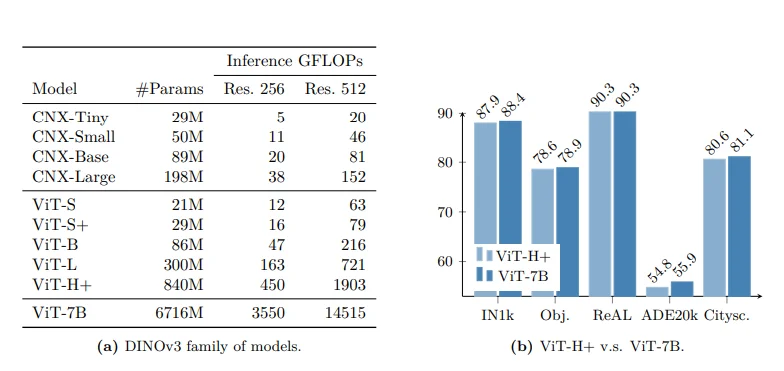
The model comes in a wide variety of sizes, ranging from 29 million parameters all the way up to 7 billion. The 7B param model is the “base” model that all the others are distilled from. The distilled models are what you will probably want to use in the real world, as they have comparable performance while being 10x smaller (or more)! There are two different flavors of small models, ViT and ConvNext. The ViT models will be higher quality and should be used for most production workloads, while the ConvNext models are super lightweight so they can be used for on device deployments.
Research
How good are LLMs at information gathering?
When learning about a new field or topic, you probably often spend a large amount of time going through a phase of repetitive research to try and find what is currently relevant for the field, something that you would hope could be automated by AI.
A group of researchers from the ByteDance research lab also thought this, so they put togther a benchmark to measure how good different LLMs were at this task.
Some examples from the benchmark:
Could you list every single concert on Taylor Swift’s official tour from January 1, 2010, to May 1, 2025, including the specific date, the concert’s English name, the country, the city, and the venue. Each show should be on its own line, in chronological order from earliest to latest.
Could you provide a detailed list of Michelin three-star restaurants in Paris, France as of December 31, 2024? I especially want to know the name, main cuisine style and exact address of each restaurant.
Note: Formatting rules omitted for brevity
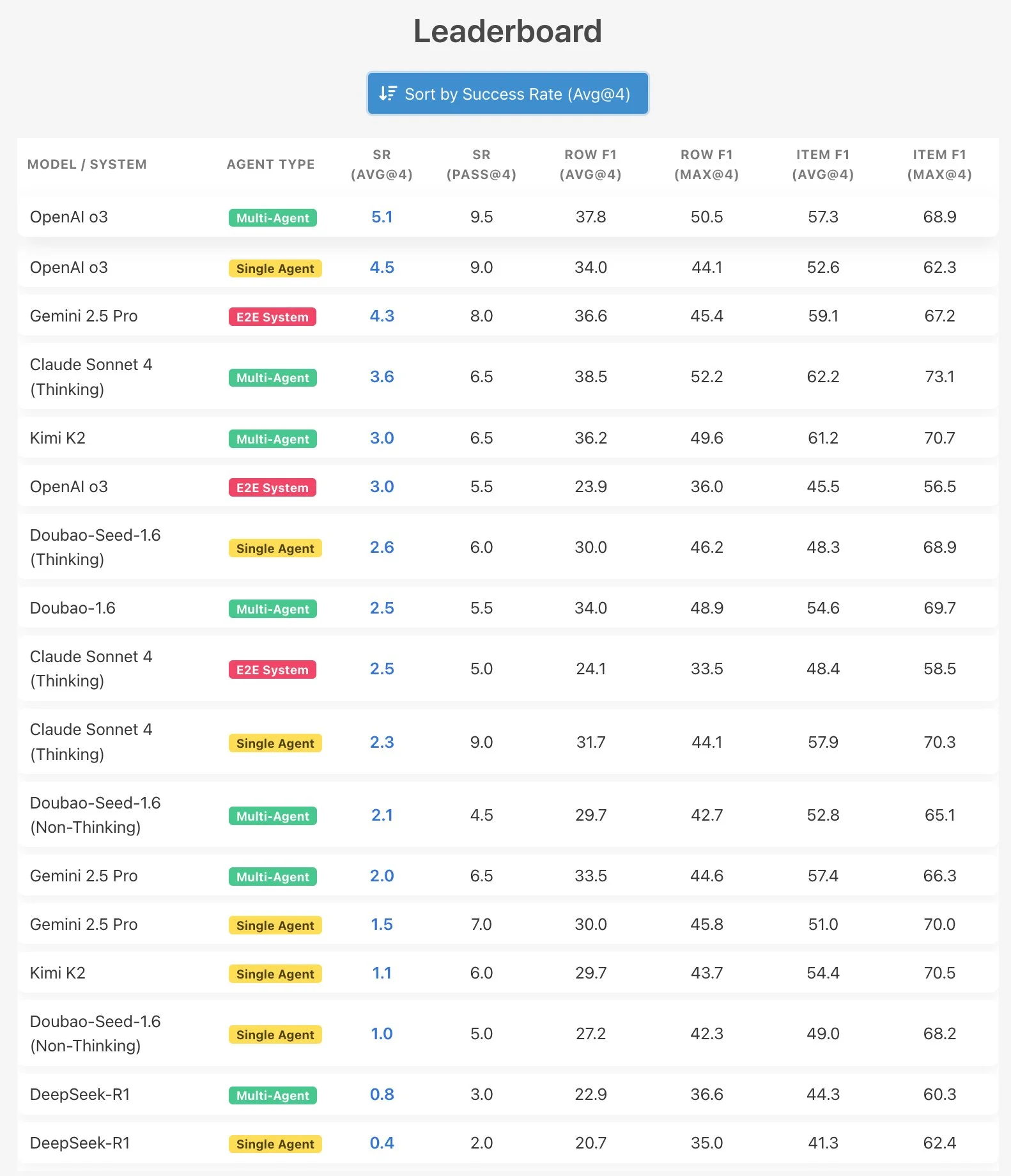
What they found is that all models suck at this, with no model scoring over 6%. They tested single agent, multi agent, and also end to end browser use systems.
The agents struggled not due to search errors, but fundamental cognitive errors. They failed at the planning stage to break down questions into simple enough sub queries. If they failed to find an answer after a single query, they would give up instead of trying others. When they did find the correct source, they would misinterpret or ignore its content, or hallucinate content that was not there.
That being said, this dataset is hard even for humans, as normal human experts only score around 20% on these tasks, although this is still almost 3x better than the AI.
Finish
I hope you enjoyed the news this week. If you want to get the news every week, be sure to join our mailing list below.
