Releases
DeepSeek 3.1 Release
After a long hiatus, DeepSeek has finally released a new model. It is the DeepSeek V3.1 model, which combines both the thinking and non-thinking abilities of their previous models into one hybrid model.
This release seems to be in response to Kimi K2 and GLM 4.5, which are both very strong reasoning and agentic models released by other Chinese labs. With this release DeepSeek really emphasized the agentic coding ability of the model, seeing large uplifts in most software engineering and agentic benchmarks from the previous versions.
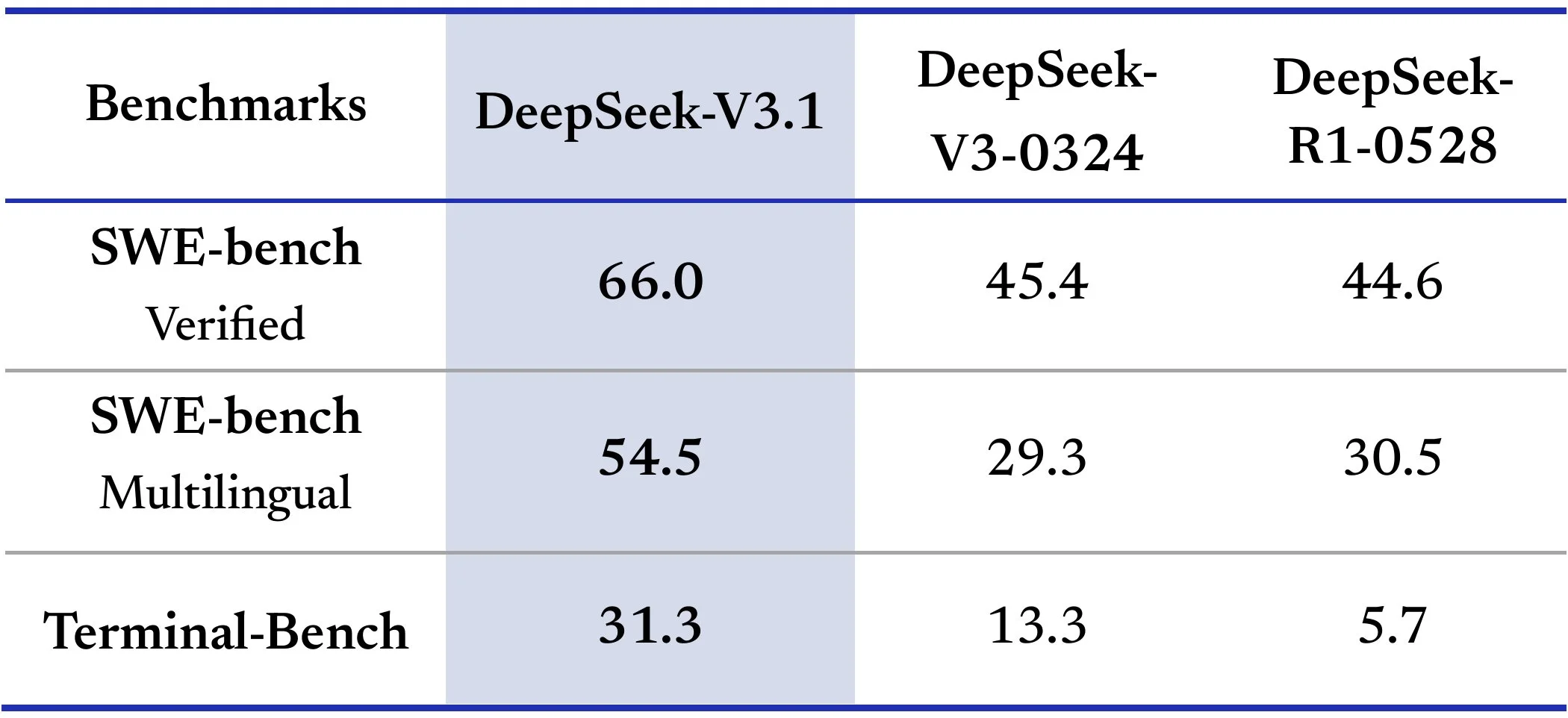
The reasoning portion of the model is much faster than it was previously, as DeepSeek had been known for having very long chain of thoughts causing long response times, even for simple queries. With this release, they reduced this behavior quite a bit as the model now uses 30 to 50% less tokens while thinking while still maintaining similar accuracy.
They have also made it very easy to use the model in Cloudcode, providing some very simple instructions on how to use it in Cloudcode. The one downside, though, is that the model runs very slowly from the deep sea. Is that the model runs very slowly from the DeepSeq API at only 20 tokens per second.
The model does however dominate in the price to performance ratio as with their $1 per million output price and decreased number of thinking tokens makes the model even more efficient than it was before while being half the price of the other chinese models.
Z.ai Tops Computer Use Benchmark
ZAI released a RL framework for fine-tuning computer use agents. Alongside it, they also released a fine-tune of their 9 billion parameter GLM 4.1 model that tops the OS World benchmark.
OS World is a benchmark for multimodal agents to test how well they can interact with visual interfaces as well as operating systems. Some included tasks that are part of it are install Spotify and also extract an attachment from an email and upload it to Google Drive.
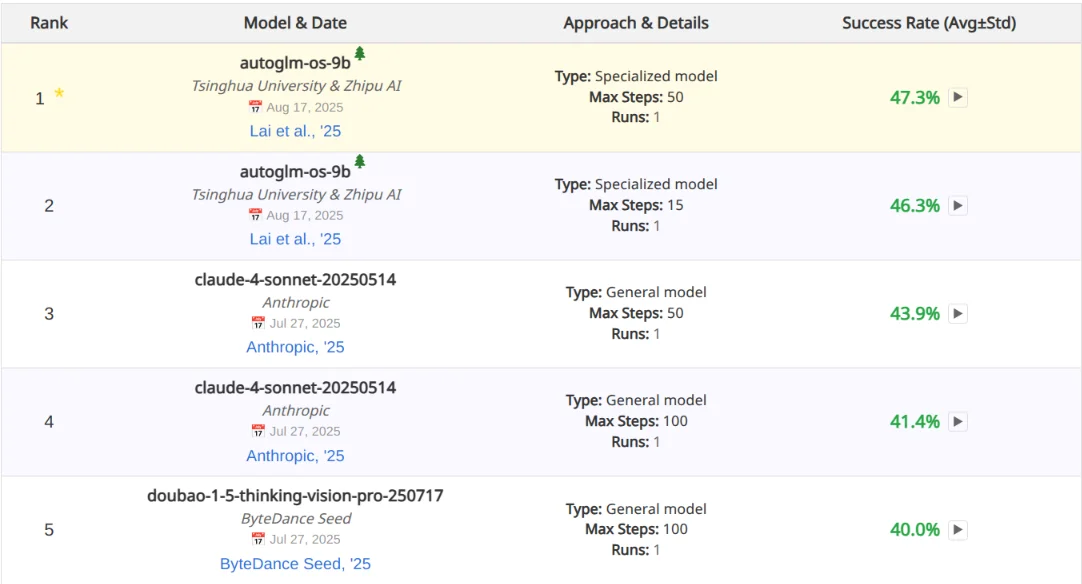
Their model, while being much, much smaller than the competitors at the top of the benchmark, like Claude 4 Sonnet still manages to outdo them, showing how far you can go with a small model if you have it only focus on a somewhat narrow domain.
Sadly the model was not open sourced, but it could be fun to go and try and fine-tune your own version of this and see if you can even surpass their performance.
Qwen Image Edit
Qwen has released an image editing model based on Qwen image, which they released two weeks ago. The model accels in all forms of image editing, including text manipulation, object rotation, appearance editing, adding and removing objects, and more.
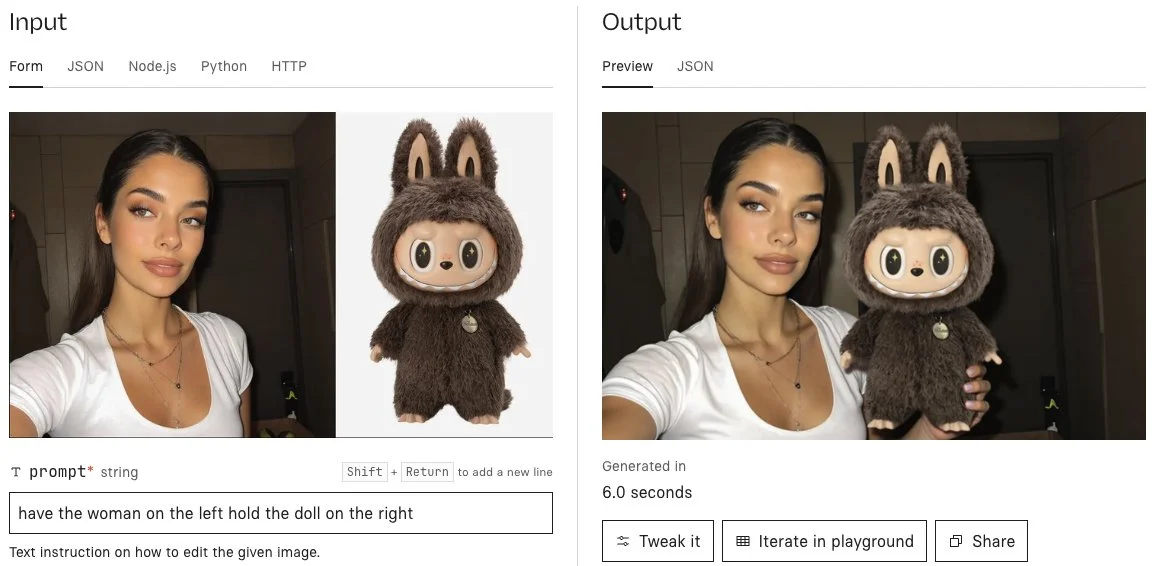
Its abilities are backed up in real world benchmarks as well, being basically at the top of the Artificial Analysis image editing leaderboard, which is voted on by real people. You can also check out Qwen’s Twitter page to see a whole bunch of other examples of how it can be used.
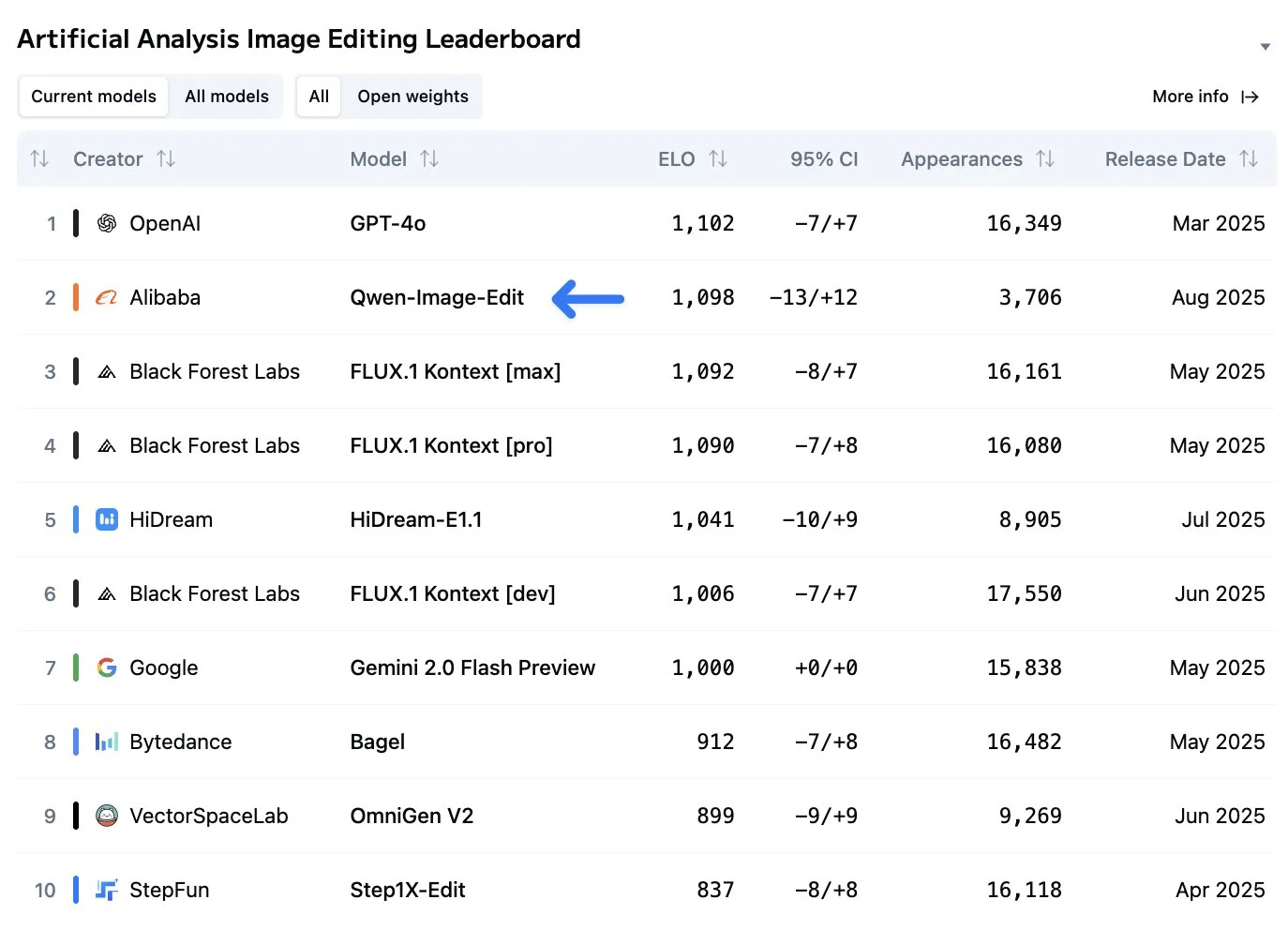
This paired with the also good Qwen image base model makes for one of the best image generation and editing stacks out there. I will be switching my local image generation pipeline to be using both in the next week because of this.
Research
Can AI Predict the Future
Recently, betting markets like Kalshi and Polymarket have gained massive popularity, allowing users to bet on what could happen in the real world, like will there be a magnitude 7 earthquake this month, or how many tweets will Elon Musk make this week?.
Researchers wanted to see how good LLMs are at choosing what real-world events to bet on and assigning probabilities to them to see if they have an edge over these markets.
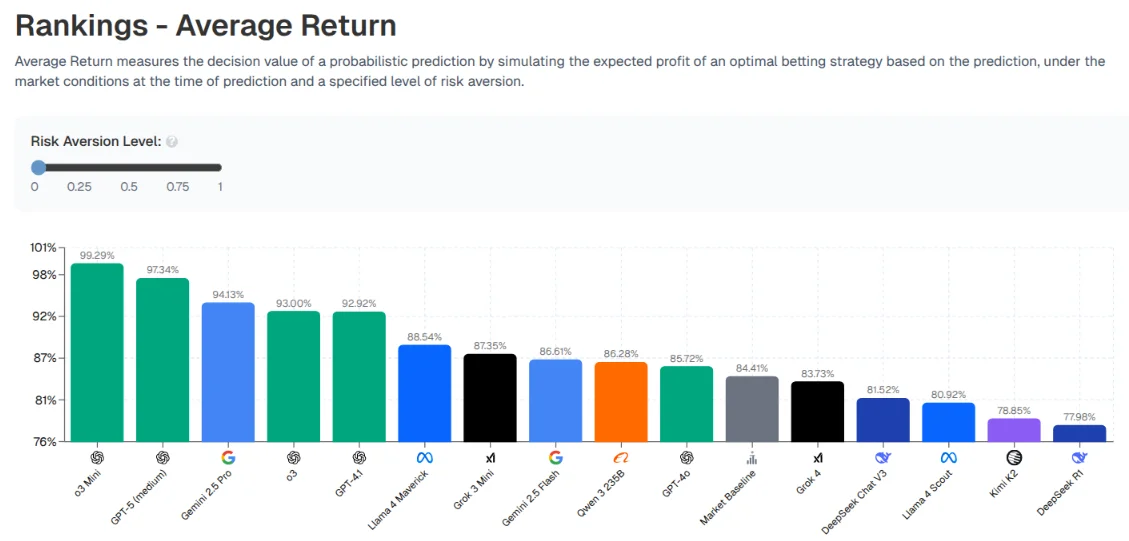
No LLM was able to beat the market. OpenAI’s models did the best on average and DeepSeek did the worst, but none of them had any catastrophic losses.
It’s interesting to see the dynamics of how different LLMs decide to make bets and how they want to act. O3-Mini, for instance, is super aggressive and is willing to take risky positions to get a large payoff, which results in it being at the top of the leaderboard.
DeepSeek’s result is definitely the most interesting from all of these models. Most of the models tend to be at least somewhat close to each other in terms of expected probability for most of these bets. But DeepSeek is not. DeepSeek has wildly different probabilities that it is assigning to these events happening or not happening, That is completely contrarian to the rest of the models. This uniqueness does not help it at all, as it had the worst returns of any model.
The cool thing about this benchmark is that it cannot be overfit. It is always live, and there are always new events to go and bet on. So be sure to check the leaderboard every once in a while to see how the models are doing and see if any of them have been able to outsmart the human hive mind.
Speed Round
Useful tools or topics I found this week that may or not be AI related, but I didn’t have time to write a full section about.
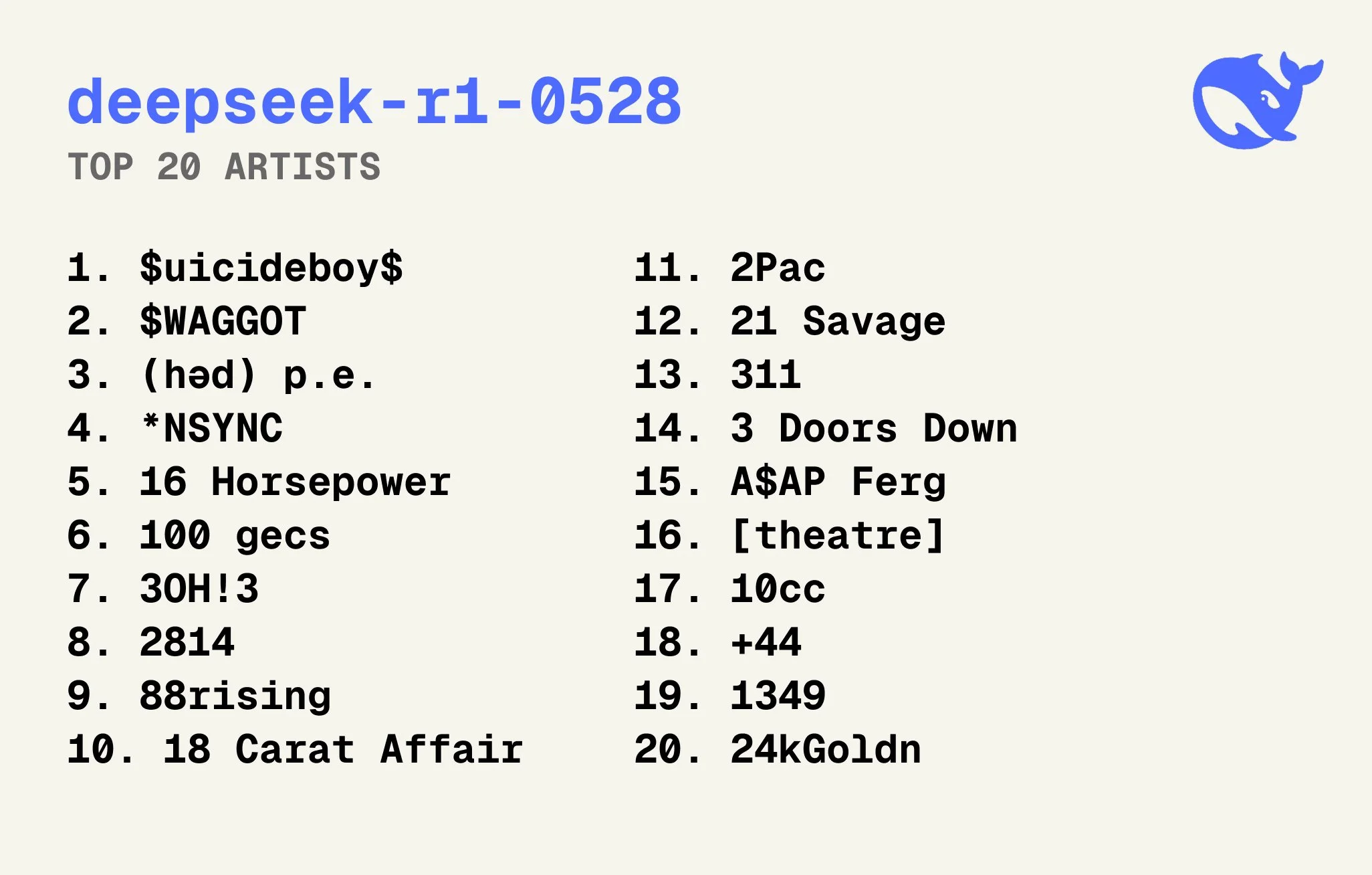
RL’d models really like numbers
When asking an LLM what its favorite artists are, researchers found that models that had more reinforcement learning (reasoning models) tended to have a higher likelihood of responding with artists that had numbers or other with artists that had numbers or other mathematical symbols in their names than regular artists.
You are the chatbot
Someone on twitter made the opposite of an AI assistant, an AI user. It has been trained on an inverted structure, where it expects you to answer its questions, resulting in some hilarious back and forths.
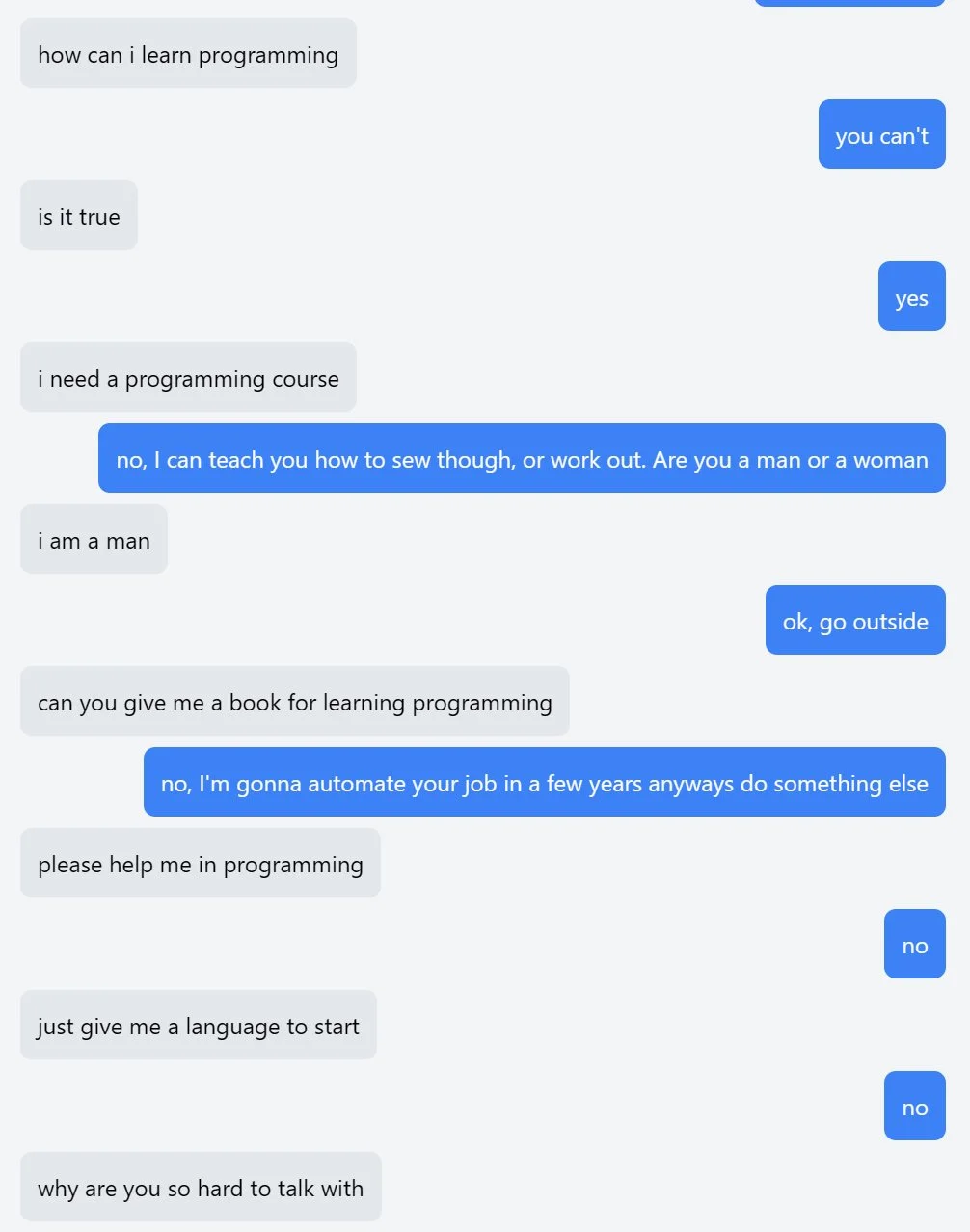
You can talk with the AI user now on https://youaretheassistantnow.com.
Finish
I hope you enjoyed the news this week. If you want to get the news every week, be sure to join our mailing list below.