Releases
Nano Banana
The previously stealth Nano Banana model has finally been claimed by an organization, with Google DeepMind announcing the release of their Gemini Flash 2.5 Image model, which they revealed had been Nano Banana this entire time.
Nano banana has been making waves as its been deployed in various image editing arenas, completely outshining its competitors, and driving record numbers of people to go and try it on these sites like LMArena and Artificial Analysis.
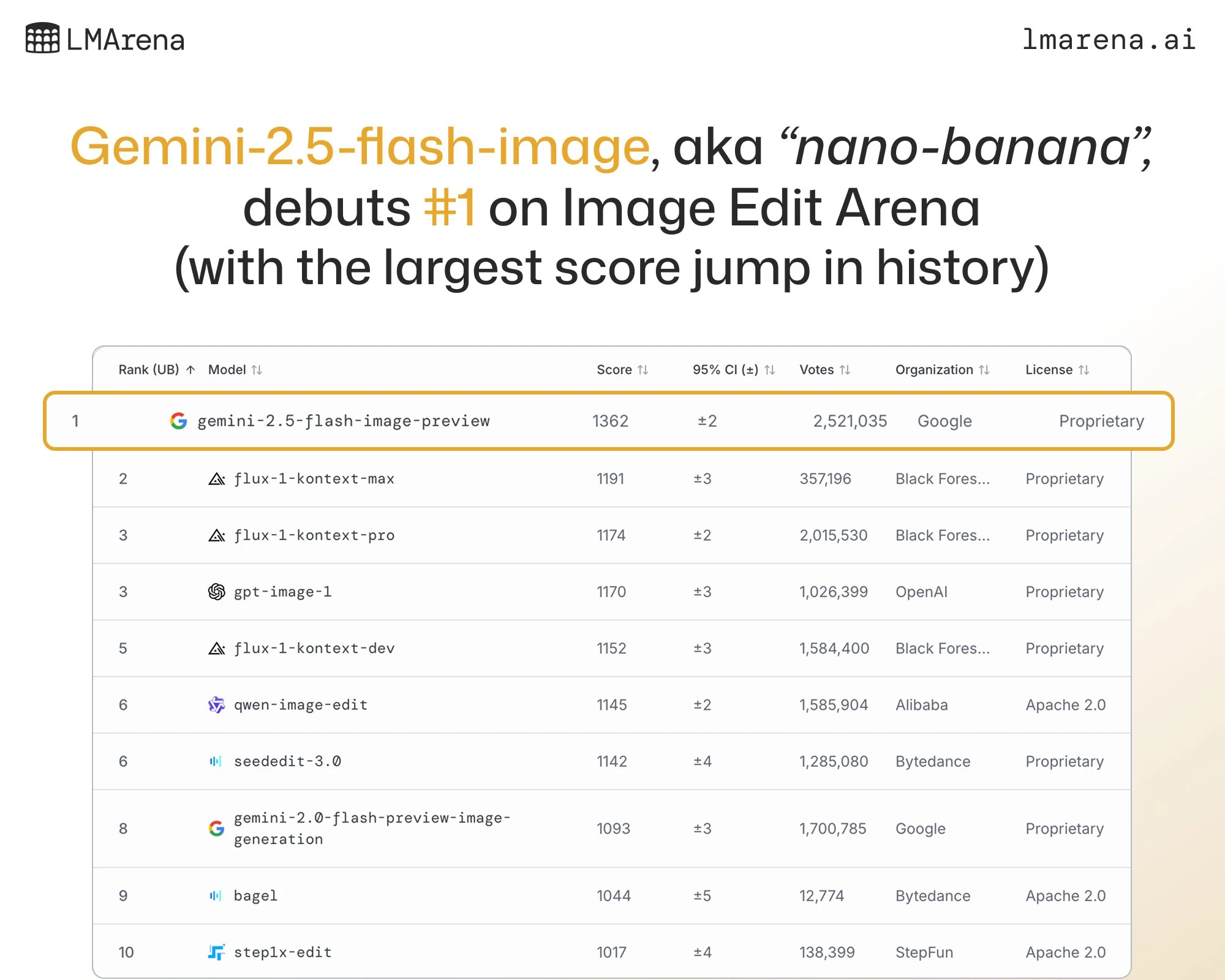
The model is available now to use for free on Google’s AIStudio and also via the API for $0.039 per image.
Qwen Audio to Video
It wouldn’t be a week of AI News without a Qwen release. This week Qwen dropped a fine tune to their WAN 2.2 video generation model, adding the ability for you to pass in audio along with a reference image, and then the model would generate a video of your character speaking that audio.
The model is good at getting the high level body movement, but it still struggles to get the actual lip syncing down. However I expect the open source community to have a much better finetune of this model in a few months, so I’ll be on the lookout for when and what that model is.
Marvis-TTS
A new challenger has arrived in the efficient TTS space, and its called Marvin TTS.
It is a 300 million parameter model with audio streaming capabilities, making it great for low resource, yet fast response time applications.
Its audio quality is definitely a step up from the current champion Kokoro TTS, but it is 5x larger, although it will have equivalent response times due to the streaming functionality that it has.
These extra parameters do get you some very welcome features, like voice cloning from just a 10 second audio clip.
The quality is definitely not the very best when compared to models 5-10x its size, but it still punches far above its weight.
You can try the model now on Mac using the mlx-audio library, or on gpu (and cpu) based systems using transformers.
Research
Environments Hub
Prime Intellect, an upstart AI lab here in the US, has released the Github for reinforcement learning environments for LLMs.
If you haven’t heard, the current big approach for RL for LLM’s has been reinforcement learning with verifiable rewards (RLVF).
In RLVF, we are able to explicitly define in code what the rewards for the model should be instead of using a separate reward model.
One common example is math, where we know for a given question what the answer is supposed to be, so we can just check the model’s output (also rewarding it for formatting correctly) to see if it got it correct or not, and rewarding it accordingly.
This makes RL training much simpler and easier to scale, notable being what XAi used to train Grok 4.
One issue the community had however was that there was no common place to see what environments other people had made or shared their own.
That is where Prime Intellect comes in, as they have made a hub where you can share and see what everyone else has made.
This is great for other researchers and model trainers, since they now have access to a large number of environments without needing to make it themselves from scratch.
Finish
I hope you enjoyed the news this week. I have been in the process of moving this week, so I haven’t been able to work on the news very much at all, so if it seemed a bit sparse that’s why.
If you want to get the news every week, be sure to join our mailing list below.