News
Sweden PM uses ChatGPT
Recently the Swedish prime minister addmitted to using ChatGPT “quite often” when in need of a second opinion or historical information. While he says he does not upload any documents, and that he uses it in a similar way that doctors do to gain more perspectives.
This comes on the heels of many AI labs lobbying to get used more in federal systems. This week OpenAI announced that each US federal agency can use ChatGPT for free for just $1 per agency. Anthropic has also publically announced that they have already trained models specific for national security customers, and that any other agencies can request access to it as well.

Releases
GPT 5
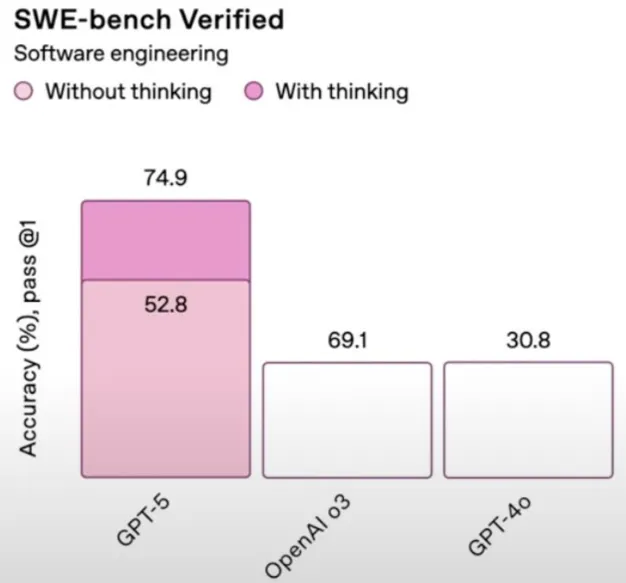
The much anticipated GPT 5 has been released by OpenAI, not without its fair share of controversy.
The announcement stream had a variety of issues, most obvious were the heinous chart crimes, including a very ironic mislabeling of the deception score.
Their model naming hasn’t improved much either.

When using ChatGPT with GPT5, your queries will now be automatically routed to the model that they think will be best to answer your question, much to the chagrin of many users. What didn’t help was that on release day, the model routing was broken, so users were being given the lower performing models when asking complex queries, resulting in poor answers.
Getting passed all of the launch day shenanigans, are the models actually good to use? The answer so far seems to be yes.
For the casual user of ChatGPT (non technical and free plan users), they will see a large bump in quality from the over 1 year old GPT 4o and 4o mini that they are used to. This also comes with a reduction in glazing from the model, to hopefully prevent less users from experiencing ChatGPT psychosis.
For the more experienced users, this seems to be a bit of a quality bump from the other models on the market. Most notably is that for coding, it seems to be a potential step up from Claude Sonnet while being 33% cheaper. It is better at follwing exact instructions than Sonnet is and is capable of pushing back on design decisions when needed.
Where is has been reported to fall short is on pure vibe coding, as it does not appear to do as well on vague prompts as Sonnet does. So if you are a Software Engineer that knows what they want, GPT 5 will be a precision instrument that you can use, while if you like vibe coding and letting the model figure it out, then you are best off sticking with what you are using now.
Finally, there has been a surprising amount of pushback from the general populace on the sudden disappearance of GPT 4o, with many equating it to losing a friend. This has caused OpenAI to reinstate the model on the ChatGPT site as an option for people to use. Remember kids, not your weights, not your waifu.
Google Genie-3
Google has released their third iteration of their world generation model called Genie-3. This model will generate custom environments that you are able to go and then walk around in, and that it will go and generate the terrain and objects within it on the fly for you. Normally, models like this really struggled with object permeance. So once an object went out of your line of sight, when you looked back in that direction, the object no longer be there or it would be changed. This model no longer has that issue. They have, according to them, an emerging capability of remembering objects and their locations previously for up to a minute.
OpenAI gpt-oss
GPT-5 wasn’t the only big release OpenAI had this week. They also released their first open-source LLM since GPT-2. The gpt-oss series of models comes in two sizes, 20 billion parameters and 120 billion parameters, both being a mixture of experts models with 3 billion active and 5 billion active parameters, respectively.
The models benchmark well, but the general sentiment for their actual quality is poor. These models have been trained on what appears to be a purely synthetic dataset, lacking essentially zero world knowledge. They are very good at coding and math, but outside of these fields they struggle and their lack of diversity in their pre-training dataset really shows.
They have almost rigid boundaries in terms of knowledge, resulting in very weird failure modes. People have been reporting that for even non-coding questions, the models will hallucinate a coding question in your input and try and figure it out themselves. Also thanks to its purely synthetic data training, the model hallucinates more than almost any other model out there, with a SimpleQA score in the low single digits, a benchmark that OpenAI made.
This is very similar in behavior to the Phi series of models from Microsoft, which are known to be purely synthetic dataset-trained models. These models perform well in reasoning and STEM, and other STEM fields, but for any other use case, they fail miserably.
Even if it weren’t for these models’ rigidness, they still wouldn’t be my choice for their given sizes. The recently refreshed Qwen3 30B MOE model has similar speeds and also similar performance while not having the catastrophic failure cases that gpt-oss has. And then for the 120B parameter model, the GLM Air model also competes directly with that within a few percent on pretty much every benchmark, even exceeding gpt-oss for agentic applications.
But hey, look on the bright side, you can now force the model to never output an em-dash ever again.
Speed Round
Useful tools or topics I found this week that may or not be AI related, but I didn’t have time to write a full section about.
Qwen
Qwen has been releasing so much stuff that they get to have their own section now.
Qwen Image
A new 20B param image generation model from the Qwen team, has very good prompt instruction following, but I find the actual image quality to be a little bit behind the top models in terms of the “AI” look that it has.

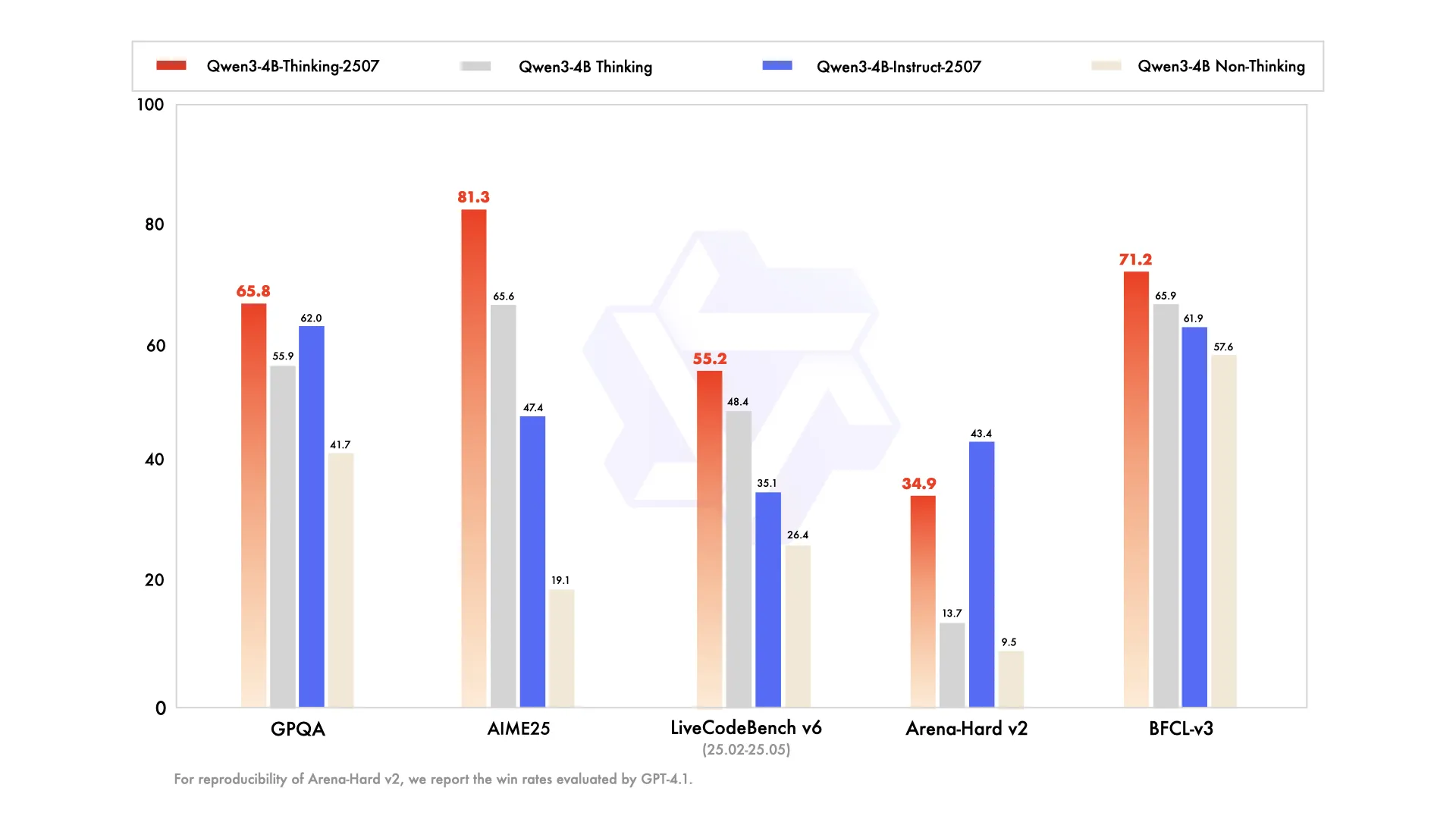
Qwen3 4B update
The Qwen LLM team has continued their post training refresh of their Qwen3 models, with two new 4B param models coming out this week. Of note there is no coder version like there was for the other two refreshes, but this does make sense as coding is a very difficult task, especially for the smaller models.
We are starting to see what sizes of models they seems to care about and think have the most impact, being the large 235B model, the 30B MoE model, and now the small 4B model.
Qwen Coder is now free
Qwen has their own Claude Code TUI competitor built on top of the Gemini TUI (not confusing at all), And like Gemini, they are offering access to their model for free, giving not just 1000, but 2000 requests everyday for free when you log in with your Qwen account.
It follows the same privacy policy as Google, so they will be training on your code, but if you are okay with that then this is a great option to go and use.
Opus 4.1
Small version bump of the already top tier Opus 4 model, performance is slightly improved across the board, but nothing revolutionary. Anthropic says that they will have “substantially larger improvements” coming in the next few weeks.
RedNote OCR model
The TikTok of China has released has an AI lab, and they have just released a SOTA VLM for general purpose OCR and image understanding. Only 1.7B params, so it should be feasible to run on the edge.
ElevenLabs Music
New music model from Eleven labs. Seems to be a step up from Suno, also allows for editing sound, lyrics, or entire sections of the songs you make. See an example of how to use it here.
Lightweight deep research model
We had previously converted a similar model called Jan a few weeks ago, and now there is competition in the space as former Stability AI founder Emad Mostaque’s new startup Intelligent Internet has released their own version that outperforms Jan by quite a large margin, especially on harder research tasks.
All the data for training and how they did it is open source.
I can see these small, on-device, personal agents being the future, as they allow for easy customizability and also users can give them access to private information without having to worry about someone else having it.
This sentiment is also echo’d by Nvidia in a recent paper they released, highlighting how small language models(SLMs) will be cheaper and faster while still being just as capable in most real world tasks.
Kitten TTS model
Kokoro TTS’s 70M params are just too much for your old Raspberry Pi? Well worry no longer, as there is now an even smaller TTS model called Kitten TTS which is only 15M params.
The voices are definitely worse than Kokoro, but still very much passable, especially if you are extremely resource constrained or care about having the lowest latency possible.
Fully AI run companies in the wild
In the future there will probably be thousands of AI companies running around, but right now there are very few. Here you can watch one person on TikTok figure out that they are a part of a company where all their coworkers and bosses are just different AI agents.
The videos seem fairly convincing, and even if it is fake, there will be something like this in the future that’s not.
MCP RL
Have an MCP server that your agent is struggling to figure out how to use? Now you can use reinforcement learning to fine tune your agent to use your server, no data required. Just give the connection to the server, and the agent will “play around with it” to learn how to use it most effectively.
Gemini is free for students
2.5 pro access, notebook LM, deep research, and 2TB of storage all included for free. All you need is a .edu email. Everyone say thanks Sundar.
Finish
I hope you enjoyed the news this week. If you want to get the news every week, be sure to join our mailing list below.