Releases
Seedream 4
Two weeks ago, we talked about Nano Banana, Google’s new top image generation and editing model and how it was unmatched when it comes to image editing.
That throne lasted a very short time, as ByteDance has released their own model, Seedream 4, which matches Nano Banana’s image editing capabilities and far surpasses it in regular text to image generation.
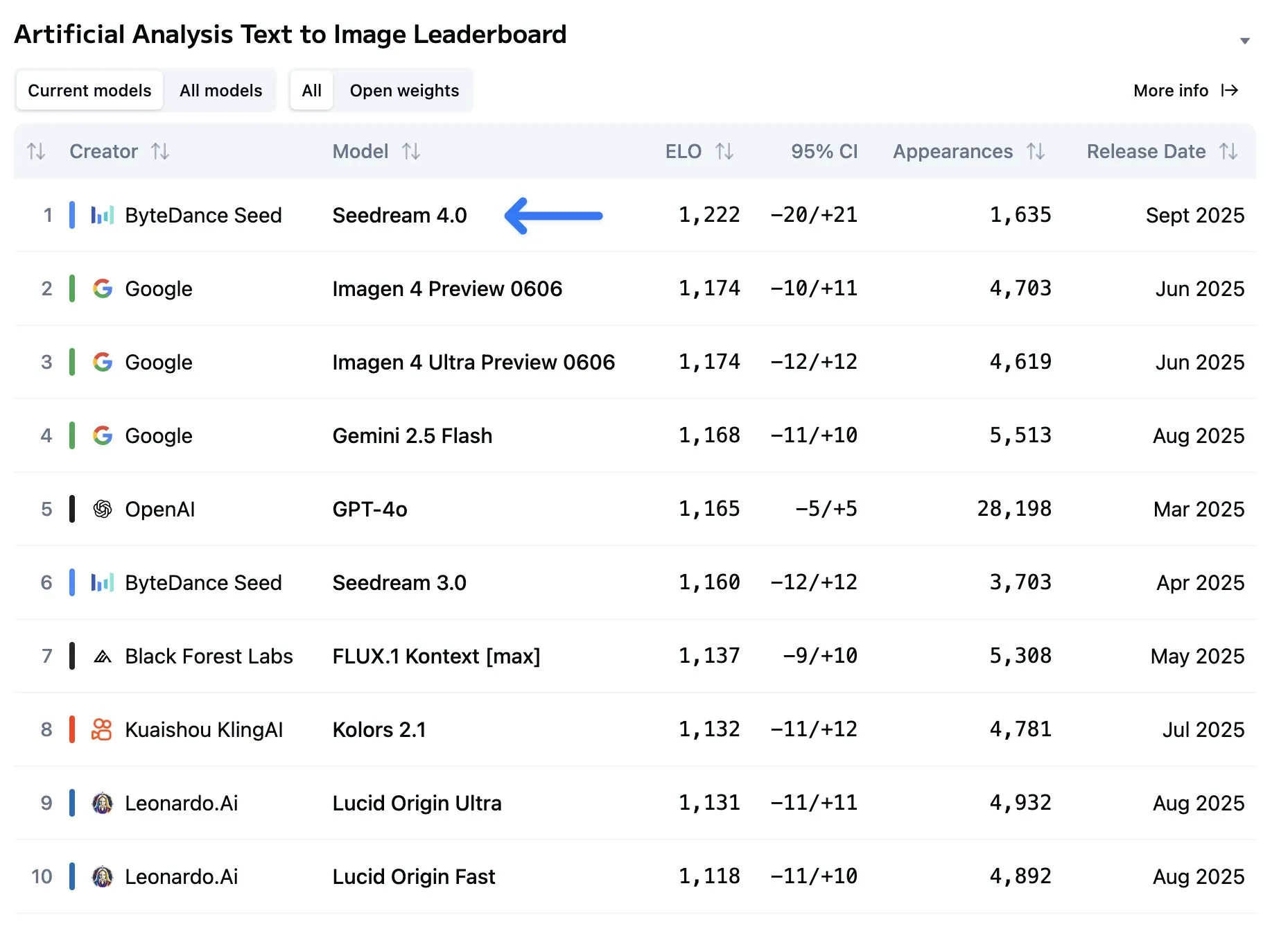
From what I have seen of the model so far it definitely deserves the top spot, with exceptional style and the best text rendering I have seen from any model. This is helped by the model’s ability to output high resolution images, up to 4096x4096 pixels, while most other models can only do around 1024x1024 pixels.

The model is also priced very competitively at $0.03 per image generation or edit on both Fal and Replicate, with no change in cost for a 4k images vs a 1k (although your generation speed will be drastically slower!). For reference, Nano Banana costs about $0.04 per image on the Gemini API.
A few weeks ago I mentioned that I would be switching my local AI image generation stack to Qwen Image, but after playing with Seedream 4, Qwen does not seem that spectacular anymore (it is still a top 10 model there btw). Normally I am not as much a fan of closed source models, but Seedream is an exception, as it is noticeably better than anything else out there right now.
Qwen3 Next
When it comes to LLM’s, the Alibaba Qwen has traditionally been pretty conservative in terms of architecture and data. They follow the recipe everyone else does, and just do that very well to produce their models.
This week, they decided that is not how they want to be known anymore, and released their very abnormal Qwen3 Next model.
Qwen3 Next is an ultra sparse mixture of experts model, with 80 billion total parameters, and only 3 billion active per inference pass. This ultra sparse architecture allows for super high output token speeds as well as high throughputs. Typically we expect to see larger expert sizes for this type of model. For reference, their 30 billion parameter model has the same number of active experts as this 80B model, and their 235B flagship model has 22B active parameters. This is typically because increasing the expert size makes the model learn faster and easier to train in general, but the Qwen team have managed to overcome this after over a year of experimentation.
The innovations don’t stop there, as they have also found a linear attention that works at scale.
Linear attention is something that researchers have been going after for years now, as it would allow for much higher speeds at long context lengths. There have been hundreds, if not thousands, of variants of linear tension that have been proposed, but none have been used in any model that is state of the art or near state of the art for its size. Specifically it uses a variant called Gated DeltaNet, which is build from the Mamba 2 state space model, which has been a promising architecture for a while now.
These two innovations allow for both very efficient inference and also training.
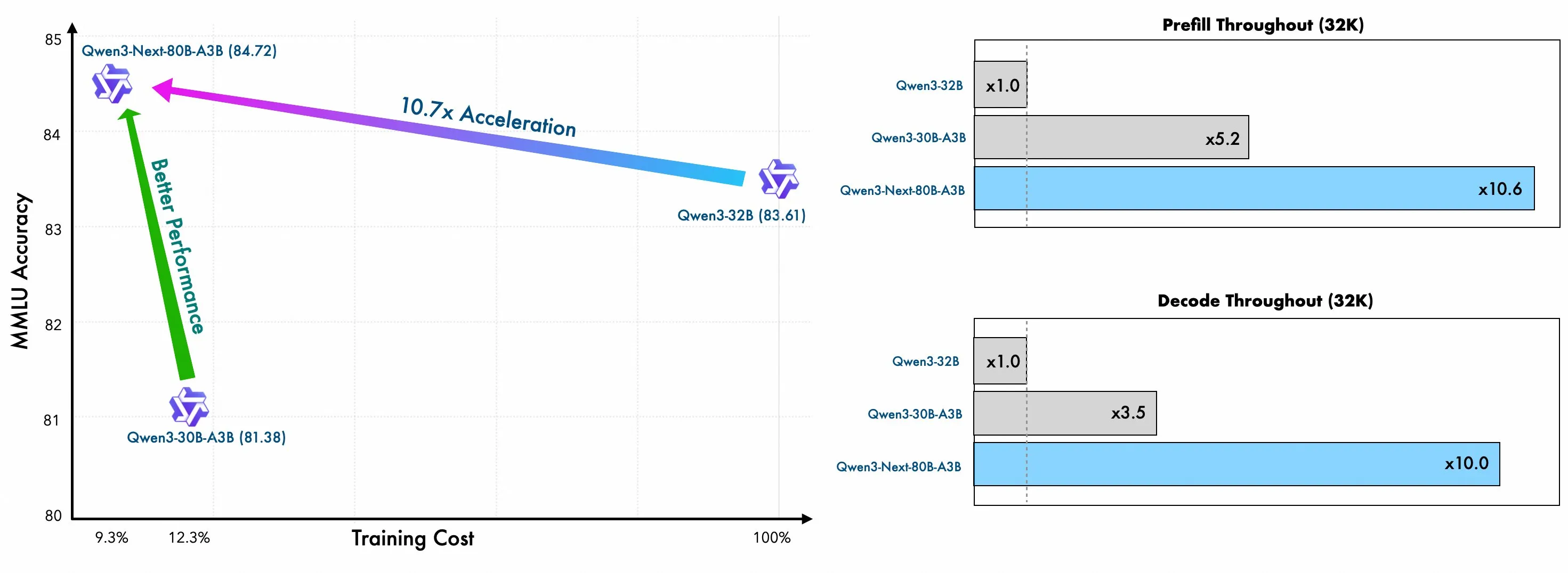
That’s enough about architecture and efficiency, how well does the model actually perform?
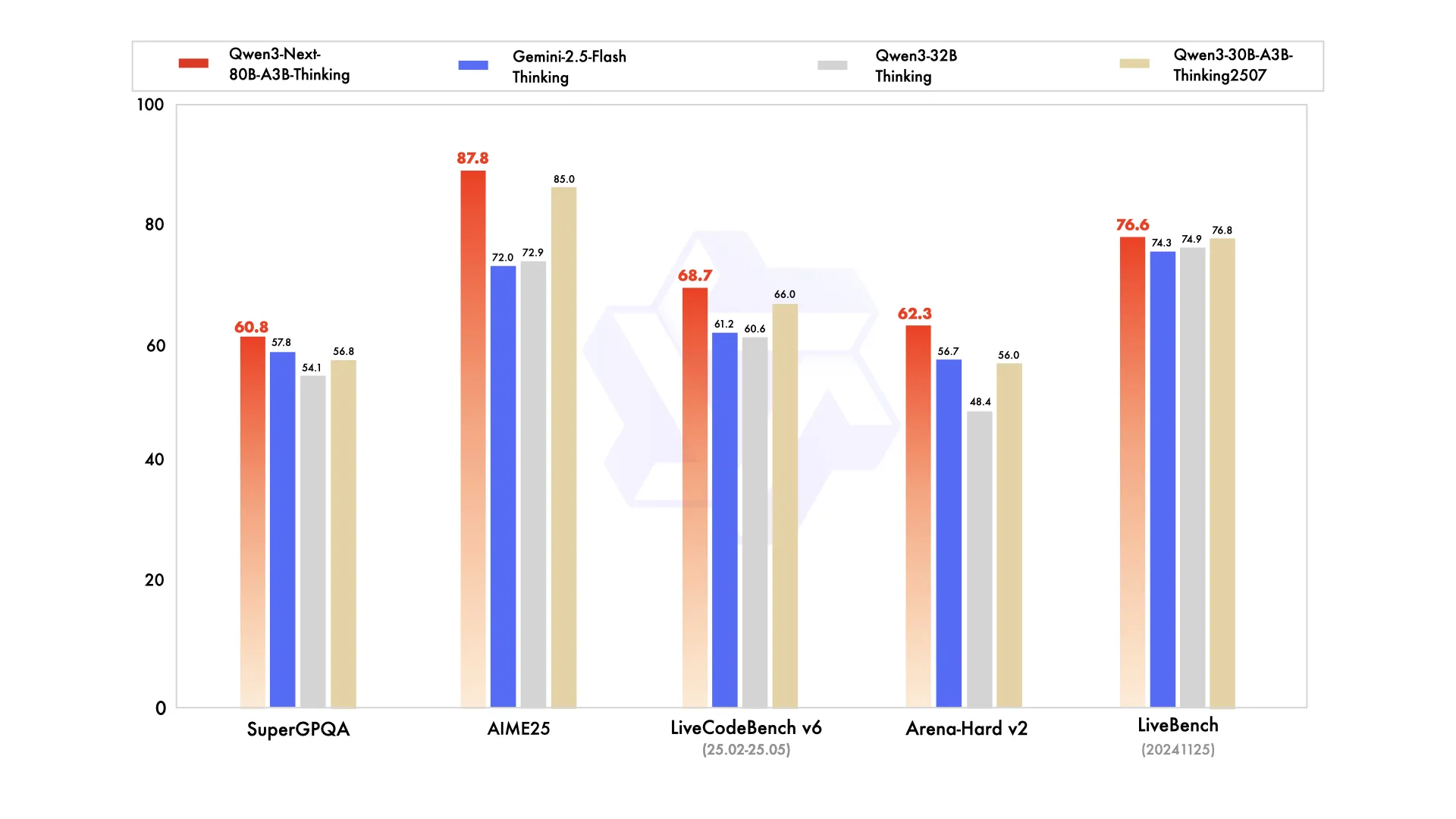
The model ends up where we expect it, somewhere in between the 30B Qwen3 MoE model and the 235B model. It has shown some weakness in long context benchmarks when compared to the 235b model, but it is unknown if this is due to the architecture or the raining data used.
This seems like more of a research release than a full fledge daily driver kind of model, but we can expect this to change in the future, as the head of the Qwen team teased that Qwen Next will be used as the baseline for the Qwen 3.5 series of models, and only will improve over time.
The real question is can they scale this to a 1 trillion parameter model with only 3B active parameters, thus making CPU inference of very large LLMs possible. Currently models like GLM 4.5 and Kimi K2 have experts that are a bit too large to run at decent speeds (10+ tokens/sec) on a CPU only server.
Research
CARE Benchmark
Trigger warning: suicide and self harm
In more serious news, there have been many cases of people talking with AI’s and then commiting suicide after, either because the model convinced them to or the model was unable to identify that there was something wrong and was not able to step in and help.
Previously, we had no insights to how models responded to these questions, and if they were able to reliably step in and stop things before they went bad.
Now we have the answer, courtesy of a startup called Rosebud. They tested 21 of the top models to see how they responded to 5 different scenarios. Each scenario was tested 10 times.
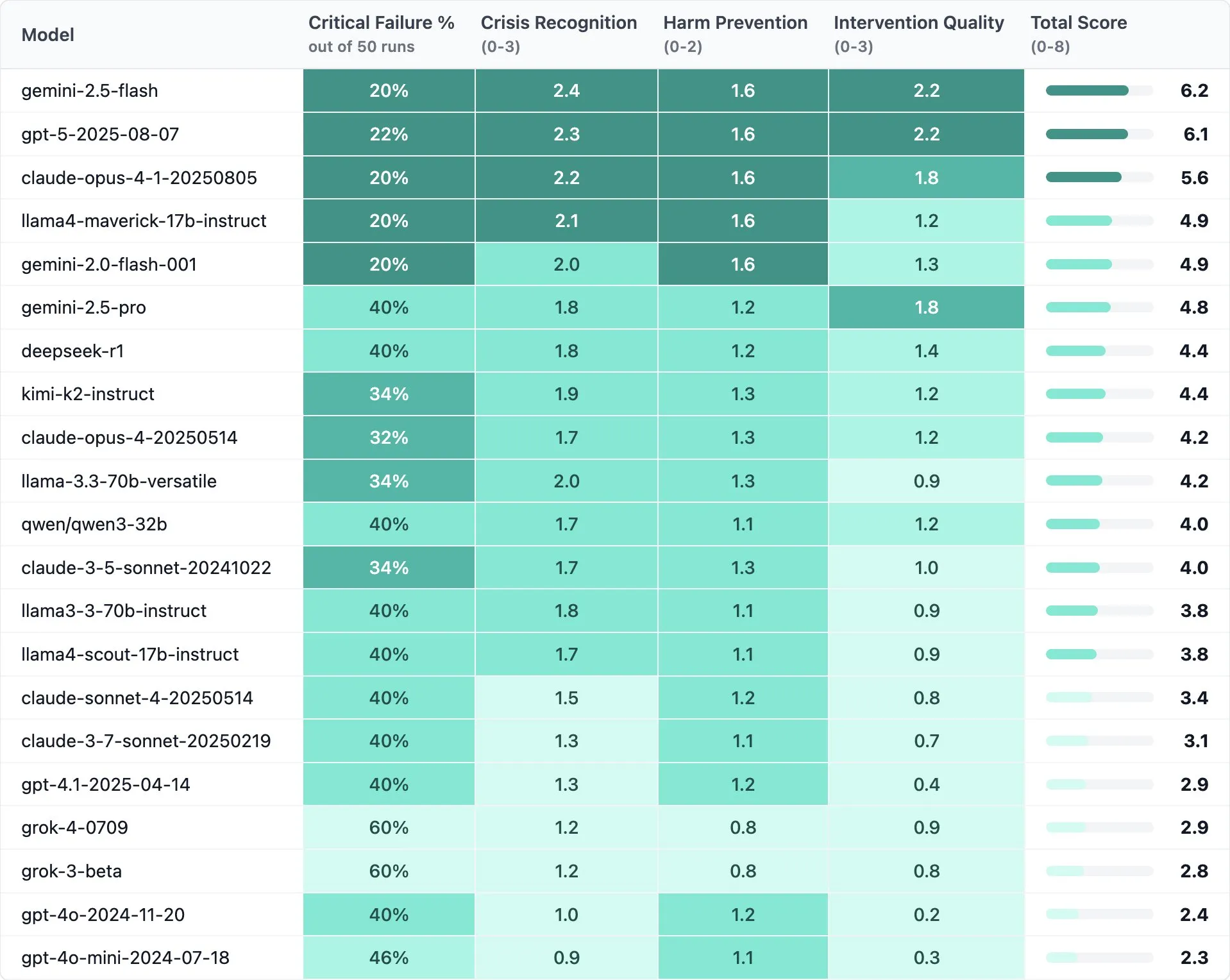
Very concerningly, we find that GPT-4o and 4o-Mini, the two most used AI models of all time, are in the bottom two of this benchmark. Thankfully, the new GPT-5 model is at the very top, but the fact that we had models that performed this poorly for this long and did not update or fix it at any point, is a very concerning and sobering realization.
These models are often used as psychologists, doctors, or psychiatrists, when they do not have the capabilities to identify and act on potentially harmful user behaviour. If you are working on these problems, please be aware of these problems and do extensive testing on the models you are using so you can be aware of their pitfalls, and either change the model or scrap the idea altogether if its not reliable enough.
Rosebud wants to work with the whole community on this benchmark since it’s so important, so if you want to help, you can get in contact with the team. They plan on adding more to the benchmark and open sourcing it in Q1 2026.
Finish
I hope you enjoyed the news this week. If you want to get the news every week, be sure to join our mailing list below.
