With most of the US taking at least a part of this week off due to the 4th of July, there isn’t that much news to report on.
News
Cursor on your phone
Cursor now allows you to be able to connect to your Github repos and then make changes for you using their new(ish) background agents. You can then come back later and review and merge the code that it makes for you. This can be done from their website or, more importantly, your phone. Just got to cursor.com/agents to try it out now.
Cursor pricing Updates
Cursor has been messing with their pricing the last few weeks, which have culminated into a much worse deal than it was previously.
A few weeks ago, they got rid of the 500 requests a month, and replaced it with unlimited uses for any of their non max models. Then they updated it so that its only unlimited free uses if you have the auto model selected, which routes the model to the most cost effective given the difficulty of the task, and when you chose a model, you now get charged base on the API pricing of the model you are using (your $20 subscription covers your first $20 of usage, but then you pay out of pocket after that).
This meant that many people found that they were getting charged hundreds of dollars all of a sudden, since Cursor did not communicate these changes very well at all. They say that you should still be able to get ~225 Claude Sonnet requests, but in my experience I would only expect to get a couple of dozen requests through before you ran out of your credits.
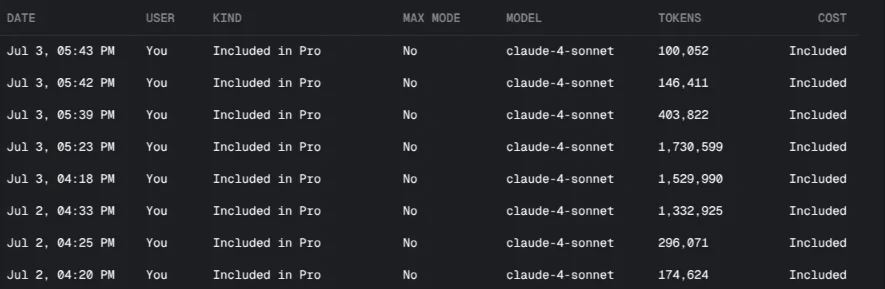
They have since repaid everyone that incurred unexpected costs and clarified their pricing model, but the age of ludacris LLM usage for cheap has ended (for Cursor at least). I have moved to Claude Code in the last few weeks using my Claude Pro subscription, and have been liking it for vibe coding more than Cursor, but it does not have as good a UX for reviewing code changes. I will make a post once I get a good workflow down with Claude Code.
Releases
New multimodal reasoning model from Z.ai
Z.ai has gone under the radar for a while now, despite having some of the best open source models available right now with their GLM4 series. Their GLM4 32B model is arguably better than Qwen3 32B, and comes with the added benefit of having the best open source base model currently available as well (the Qwen team didn’t release the base model for the Qwen3 32B and 235B models).
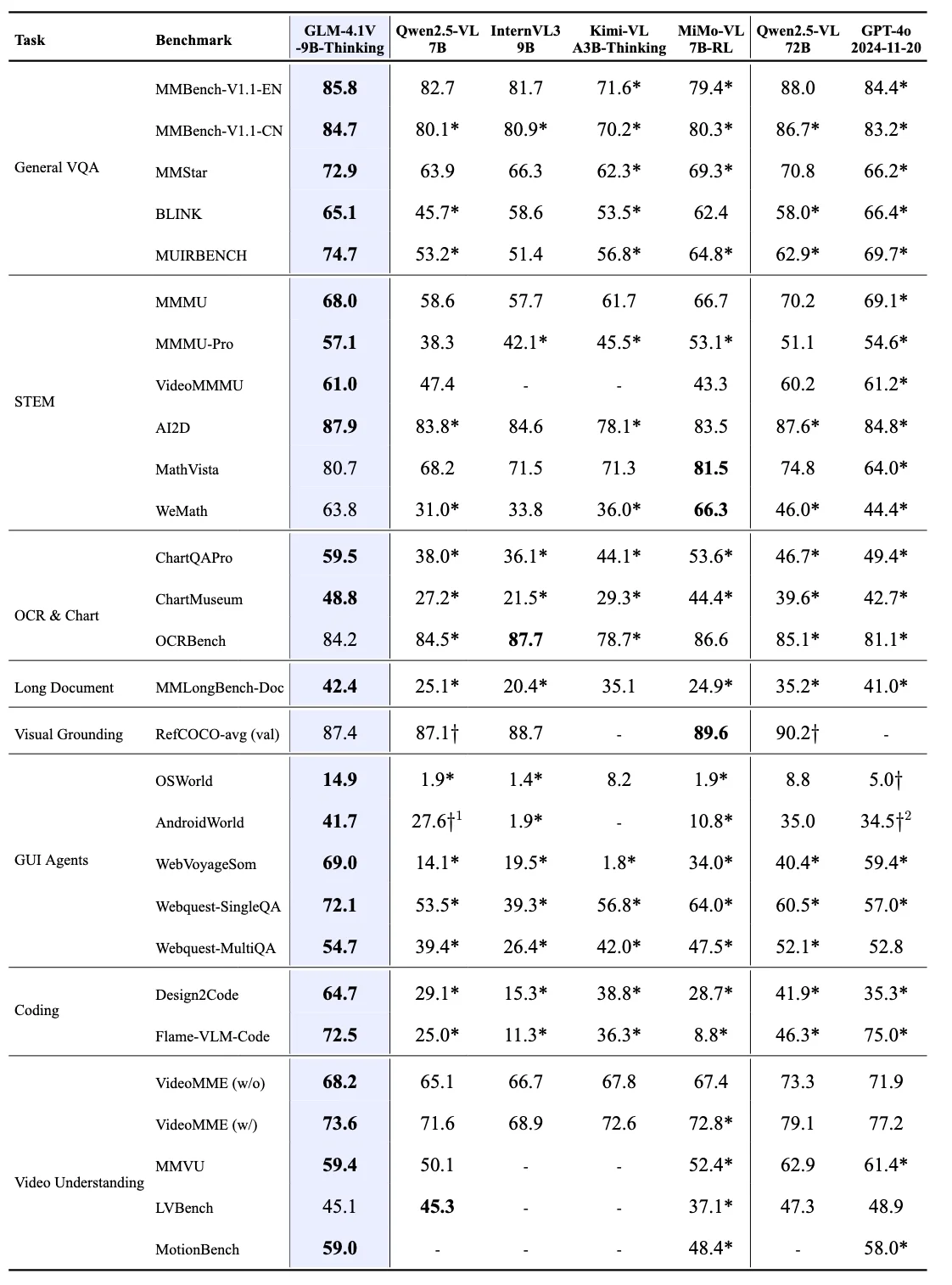
They are adding to their GLM4 series, releasing a vision reasoning model based on their GLM4 9B model. It outperforms most other models its size, and also outdoes GPT-4o on image understanding and reasoning tasks. It can also do video understand as well, also ranking above other open source and closed source models.
Gemma 3n
Technically a release from last week that didn’t make the cut, Gemma 3n is a open source release from Google, meant for on device deployments. You are able to very the number of parameters used (using an architecture called MatFormer) which makes it larger or smaller, depending on the difficulty of the task or the resources of the device it is running on. It is truely multimodal as well, allow both image and audio input along with text. The benchmarks look good, especially for conversational use, with an elo over 1300 on LMArena.
There is a Kaggle competition with over $150k in prizes centered around the model. You can find and use the model on pretty much every platform that you use for LLM inference already, so you can start building with it now!
NOTE: There is currently a bug in the TIMM library (which has the modeling code for the vision transformer part of the Gemma 3n model) that is drastically negatively affecting the image understanding of the model. Until this is fixed, don’t expect any meaningful outputs from image inputs.
Research
Automated LLM Speedrunning
Andrej Karpathy released the nanoGPT library as a simple, fully self-contained example for training an LLM. Since its release, people have been working on increasing the speed to train the model to a specific target metric (3.28 cross-entropy loss on the FineWeb validation set).
This has resulted in a plethora of changes that has caused the time to train the model to go from 45 minutes down to under 3. Researchers at Meta wanted to see if the models, given the code, could go and find these speedups and implement them.
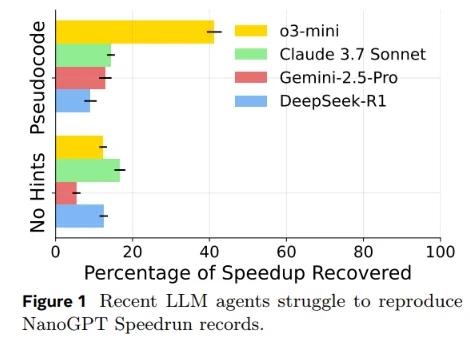
To jump to the conclusion, the models were pretty bad at this, with no models able to get more than 20% of the speedups when on their own, and even when given full pseudocode for the changes that resulted in the speedups, the models could still only at best get 40%.
LLMs may be good at web dev, but they still have a long way to go for system style programming.
Finish
