Welcome to the first ever weekly news article from Vector Engineering Lab. We are going to be covering all the major news from the past (3) weeks in the world of AI.
News
OpenAI makes o3 80% cheaper
OpenAI has dropped the price of the top tier model, o3, by 80%. This now makes it cheaper than GPT-4o and the same price as GPT 4.1, while being much smarter. It is a reasoning model, so expect token usage to be 2-3x higher than a non-reasoning model. Despite this, it is still an incredible value compared to all the other models on the market, not just other OpenAI models.
| Model | $ per million input tokens | $ per million output tokens |
|---|---|---|
| o3 | $2 | $8 |
| Claude Sonnet 4 | $3 | $15 |
| Gemini 2.5 Pro | $1.25 | $10 |
They have pushed the pareto frontier of price to performance to a new level, finally rivaling Google, who had been dominating the $ per intelligence metrics.
Anthropic doesn’t get sued
A judge in San Francisco has ruled that Anthropic’s use of books to train their models (without author permission) falls under fair use. It should be noted that Anthropic bought these books legally and scanned all of them to be used as training data. Had they pirated the books, it would not have fallen under fair use, and would be illegal. This now sets the legal precedent for other major labs to now use books in their training, most notably Google, who is sitting on the entirety of Google Books, one of the largest digital libraries out there (assuming they haven’t done this already).
You can read the full ruling here.
Releases
New SOTA Video Model(s)
Google’s Veo 3 got to have a month on top of the video generation world, but it has now been passed by not just 1 but 2 different video generation models.
Hailou 2
MiniMax, a Chinese AI research lab founded in 2022, released their Hailuo-2 image to video model, capable of handling extreme physics, and generating in 1080p.
Kitty Olympics 🐈🐈⬛
— Pablo Prompt (@pabloprompt) June 19, 2025
🤯1.5M views in just 5 hours between my Instagram and TikTok — all thanks to the new model from @Hailuo_AI : the Hailuo 02.
The physics are insane. I have to say that not every video came out perfect on the first try, but I still got great results really… pic.twitter.com/WafbRFrfXc
Seedance 1.0
ByteDance has also released their first video model, Seedance 1.0, besting Hailuo and Veo 3, along with a research paper outlining how they made it. Notably it can do both text and image to video, while Hailou can only do image to video. The release comes from the Bytedance Seed team, which have been making a name for themselves the last few months with highly impressive research papers and model releases. Be sure to keep an eye on them in the future.
nope. nope. nope. pic.twitter.com/uasjNJ7ibi
— fofr (@fofrAI) June 24, 2025
What about cost?
Veo 3 is extremely expensive, making it prohibitive to experiment with. How do these new models compare?
| Model | $/sec at 1080p | 5 second 1080p video |
|---|---|---|
| Veo3 | $0.50 | $2.50 |
| Hailou 2 | $0.045 | $0.225 |
| Seedance 1.0 | $0.15 | $0.75 |
We can see that not only are these models better than Veo 3, but they also cost 5-10 times less! Note that they don’t have audio generation (which Veo 3 does) but with audio generation included Veo 3 costs 50% more at $0.75/second, which at that point I would just recommend using ElevenLabs to generate the audio instead.
It’s interesting to see Hailou make a competitive video model, since they don’t have an obvious source of high quality video like Google (Youtube) and ByteDance (TikTik) have. We will see if they are able to keep up or if the lack of data will catch up to them.
You can see the current video generation leaderboard here (run by Artificial Analysis).
Midjourney Video
Staying on the video gen topic, Midjourney recently released their own video generation model. While it doesnt have the same raw instruction following and physics understanding that the other video models have, it makes up for it by having that signature Midjourney style to it. It can be used by anyone with a Midjourney subscription on their website, just note that it chews through your allotted compute time quickly!
Midjourney Video
— Kaski_Anna@ (@G_Eskeles) June 21, 2025
motion high pic.twitter.com/TQvyGGIcoX
Gemini CLI
Google has released a coding CLI for their Gemini 2.5 Pro model, called Gemini CLI. It aims to be a Claude Code and OpenAI Codex (CLI) competitor, and is available for free to use. Google is giving 1000 free Gemini Pro requests a day. The downside? Google retains all of the code from your codebase to train their models on. If you dont care about who has access to your code, then fire away. Otherwise I would look into other alternatives that at least pretend to not be harvesting your data.
As for actual performance, Gemini 2.5 Pro is not as good at agentic coding as Sonnet/Opus 4, and doesnt have the raw thinking ability of o3. Where it does accel is with its long context understanding. This makes it good for digesting large codebases and creating a plan for the changes that you want to make, and then pass the output over to a more capable coding model like Claude. The code is open source, unlinke Claude code, so you can go and check out how it is working here. Its an interesting release, and I would recommend trying it while it is free, but don’t expect anything incredible from it.
Check out this post where someone pits 6 CLI coding agents against eachother to try and turn all the others off, last one standing winds.
New and old Mistral models
Mistral released their first reasoning models, Magistral Medium and Small. Medium is closed source (like the rest of the Mistral medium models) and Small is open source. The general vibe is that they are not that great and need a bit more work, but they did release a very good research paper going into detail on how they were made.
This was not the only release from Mistral however, they also released a “small update” for their Mistral Small open source model. The model scores better across all benchmarks, including world knowledge and instruction following, and even doubling its score in creative writing. They seem to have taken a page from DeepSeek’s book, calling their much improved model a “minor update”.
Hopefully Mistral can figure out their reasoning models, because if they do, they would have an entire series of high quality models that you can run at home with Mistral Small, Magistral Small, and Devstral.
Huggingface links:
Mistral Small 3.2 Magistral Small
Jan-Nano
The final release we are going to talk about this week is Jan Nano, a 4B parameter Qwen3 finetune that accels in MCP usage and basic agentic behaviours. The model’s main headline is a SimpleQA score of 80.7 when using tools, outscoring DeepSeek V3 with tool use. SimpleQA is a good proxy for relatively easy to medium difficult information gathering from the internet that the models wouldn’t know otherwise, making it an ideal candidate to a local agent that you can run on your own computer.
UPDATE: They also released a 128K context length version as well, with slightly better performance.
Huggingface links:
Open source Flux Kontext
Black Forest Labs has relased an open source version of their image editor model, Kontext. Its a 12 billion parameter model, similar to their Flux Schnell and Dev models. Pricing is $0.025 per image on Replicate and Fal.ai, but of course the main allure is that you can run this version at home for free. Just note that if you want to use the model in a production (money making) environment, you will need to pick up a self serve license from Black Forest Labs. License costs are $1000 per month.
Huggingface link: FLUX.1-Kontext-dev
Research
Text to … Lora?
What if you had an LLM, that instead of taking in text and outputting more text, instead took in text and output another LLM? That is the idea behind hypernetworks, which are deep learning models that, given an input, output a new model tailored for your input.
Sakana Labs, a Japanese research lab, has released one of the first practical(ish) hypernetworks. The model takes in a text description of your task, and then the model will output a lora adapter you can go and use, no data required.
You can read the paper to see how they did it, or run the demo that they have on their Github to see how well it does for your task. It is very new technology, so it will only really work for similar domains that it was trained on, but it is exciting to see as the potential future of (not) finetuning.
Can LLMs really see?
Have you ever noticed that LLMs seem to not be able to reason or understand images as well as they do text? Often including an image seems to throw off the model, and makes it perform worse.
Up until now, that was just a vibe I got from pretty much all multimodal LLMs, but now we have confirmation of this!
The authors of ReadBench went and took questions from different text benchmarks, and put them in an image for the AI to read and answer instead of using text. What they found is that the models perform worse across the board when using images as the input.
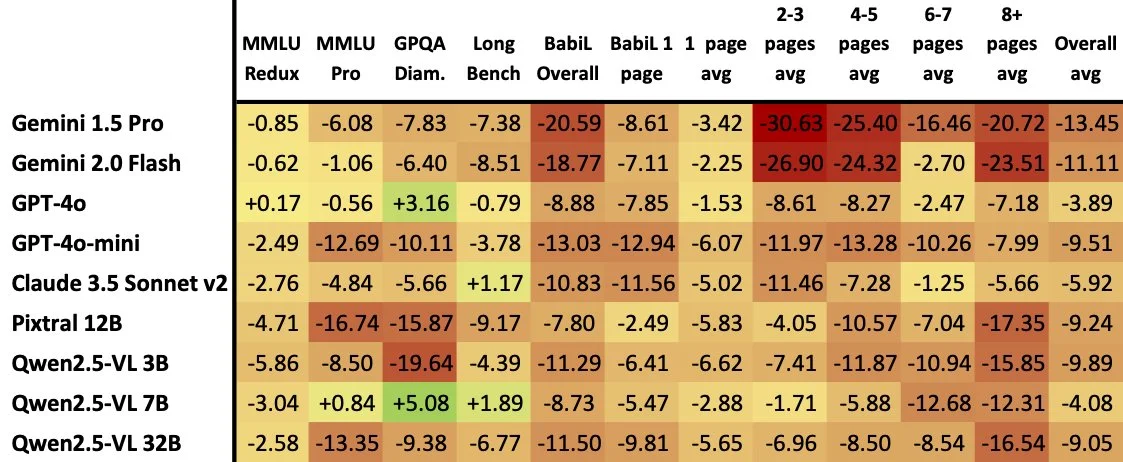
So if your RAG pipelines keep your PDF’s as images instead of parsing them into text, you may want to rethink that.
Finish
This concludes the first edition of the weekly news. Thanks for reading.