News
OpenAI postpones open weight release
OpenAI has been saying for a while that they want to release an open weight model, but it appears that we will have to wait a bit longer, as Sam Altman announced that they are delaying the release date of the model, which was supposed to be next week. This is to have “time to run additional safety tests and review high-risk areas”.
There is very little known about what the model may be, as even the potential release date was only rumored until Altman confirmed it this week. This will be OpenAI’s first open weight LLM since GPT-2 back in 2019. Altman has said previously that they were targeting an O3 mini level model, as that would put it near SOTA for open source (when he said it back in February). But as we will see, this bar has been raised with many releases matching or exceeding o3 mini quality that can be run on a single GPU at home.
Releases
Kimi K2
A relatively unknown Chinese lab, Moonshot AI has dropped an open source, MIT licensed model that is near SOTA, not just for open source models, but for all models in general, which is cited a potential cause for the delay on the OpenAI open weights release.
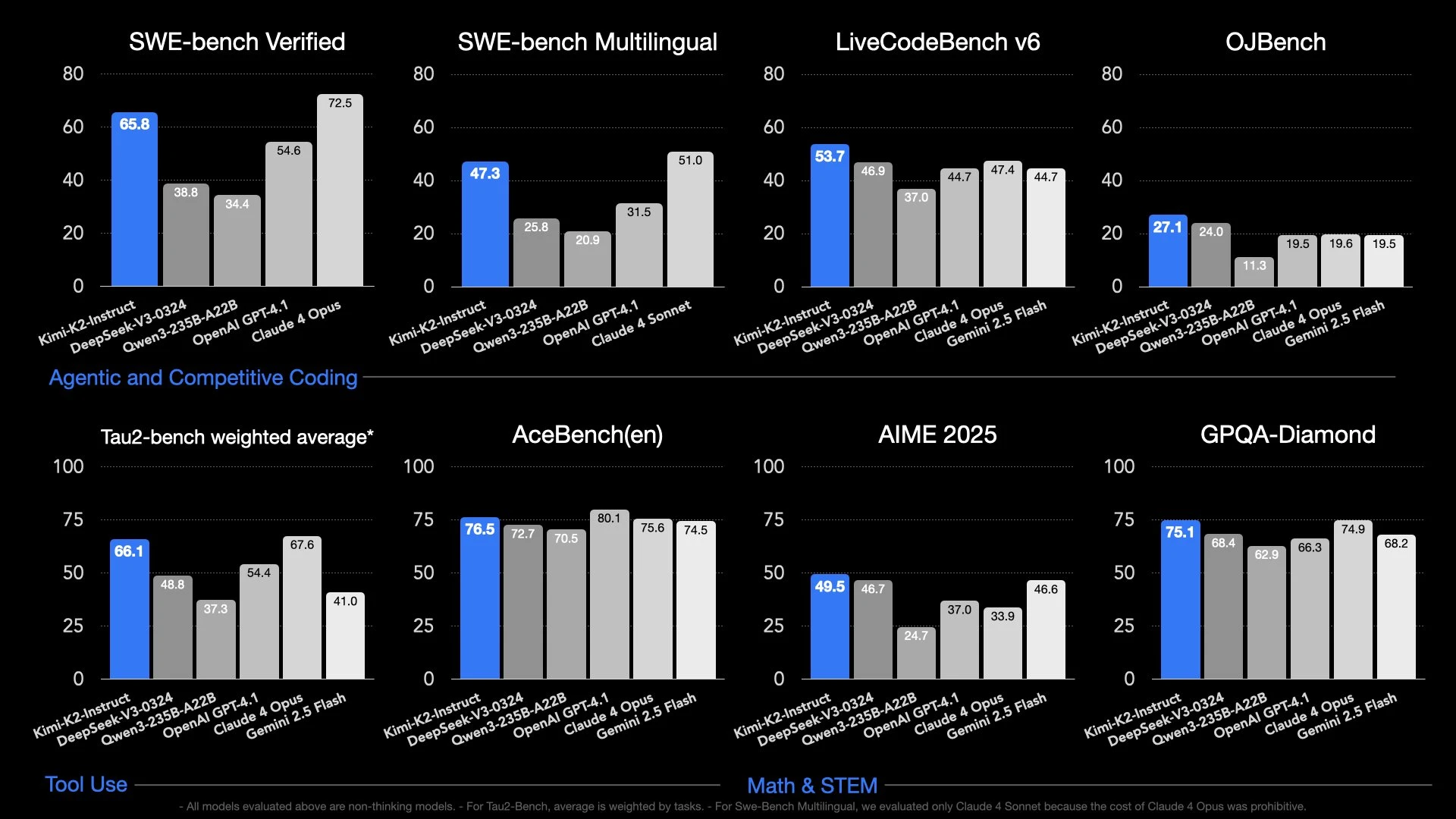
The model was trained for and excels at agentic tasks, but also is very good at creative writing, something that has become a pattern for these smaller Chinese labs like MiniMax and Z AI. It does all this without being a thinking/ reasoning model, which has been the main driver of progress for LLMs in the last 6 months.
Unlike the Grok 4 model (discussed later), Kimi K2 passes the private vibe evals for most users, with its closest competitor being Opus 4, which is truly remarkable for an open source model you can (theoretically) download and run at home.
Why do I say theoretically run it at home? Well that is because it is a 1 trillion parameter mixture of experts model, with each expert being 32 billion parameters each. This makes it almost double the size of DeepSeek R1, which has “only” 600 billion parameters. That being said, if you have the over 600GB of memory required just to load the model in 4 bit, you can already run it using Ktransformers at a reasonable 10 tokens per second, assuming you also have a decent consumer GPU to help accelerate things.
While at home inference will be unattainable for most people, the model should be runnable on a single H200 or B200 node at 8 bit quant with VLLM or SGLang, or on a H100 node if you are willing to go down to 4 bit quantization. The model should also be runnable on pretty much every other modern inference framework as well, as it uses the same architecture as DeepSeek V3.
You can try out the model right now for free at kimi.ai, or via their API. Since the model is open source, you can expect more providers for it to pop up over the coming weeks. Speaking of using the model, how much does it cost for API access to the model? One of the reasons behind DeepSeek’s success was its very cheap price relative to the competition. Does Kimi continue this trend?
| Model | $ per million input tokens | $ per million output tokens |
|---|---|---|
| o3 | $2 | $8 |
| Claude Sonnet 4 | $3 | $15 |
| Gemini 2.5 Pro | $1.25 | $10 |
| DeepSeek R1 | $0.55 | $2.19 |
| Kimi K2 | $0.60 | $2.50 |
Yes, it does. While not being as cheap as R1, it has the hidden benefit of not being a reasoning model, which means it will use far less tokens than all the other top models right now, which will result in lower actual prices when using the model. The Chinese have done it again, making a model that rivals the best that the west has to offer, open sourcing everything while doing it.
Grok 4
The XAi team announced their new Grok 4 model this week on (a painful to listen to) livestream. The model uses Grok 3 as the base, and instead of doing continued pretraining to make the base model better, then instead fully focus on fine tuning the model using reinforcement learning.
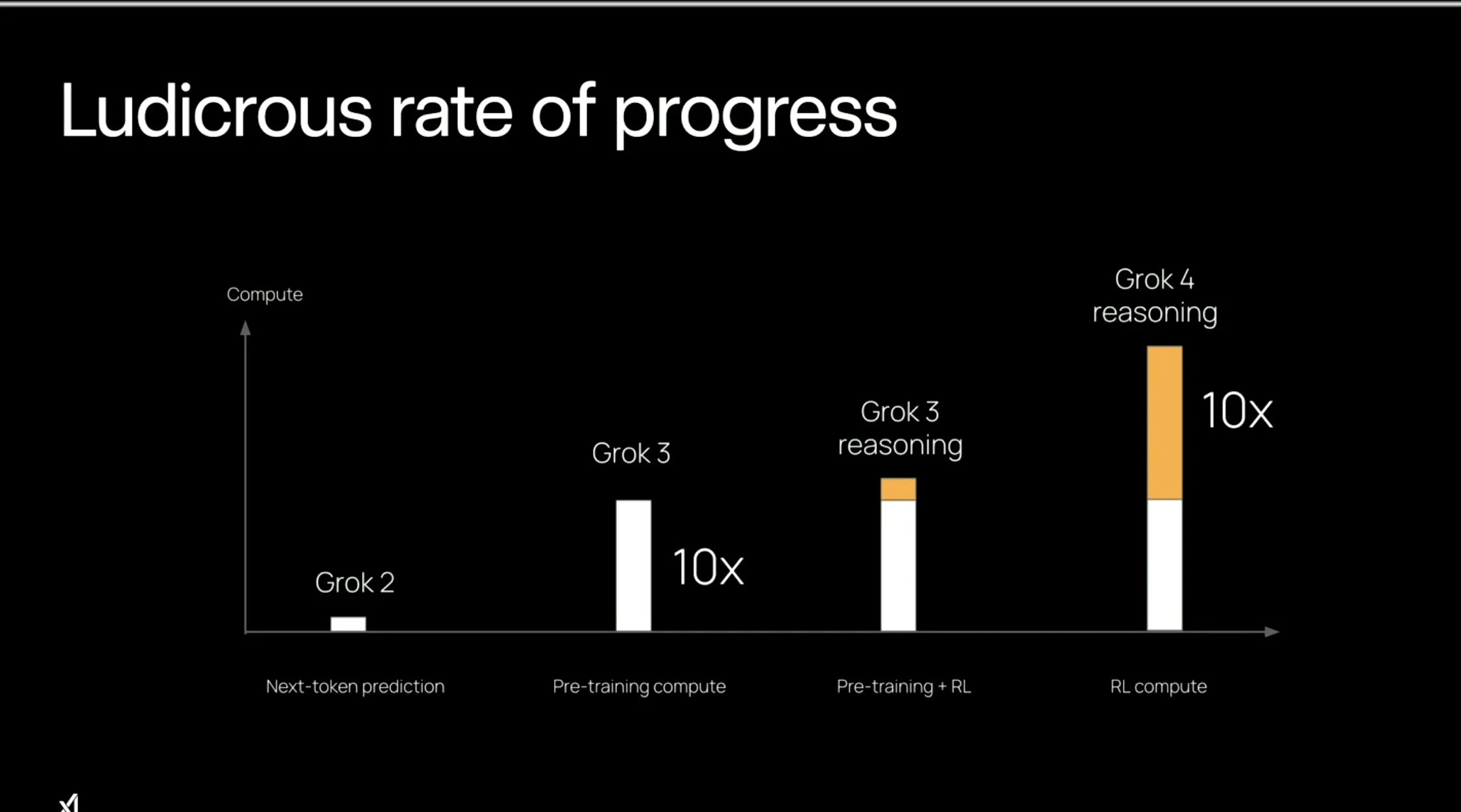
Grok 4 comes in 2 variants, Grok 4 and Grok 4 Heavy, with the heavy version just being best of 4 sampling of Grok 4. That means that they run your query through Grok 4 four times and then use Grok 4 as a judge to pick the best answer to give to you.
Despite crushing it on benchmarks, the public’s vibe check seems to be of the mind that its similar to the other top models like o3, Gemini 2.5 Pro, and Claude Sonnet/Opus, but not really exhibiting any revolutionary behaviour that would make you want to switch.
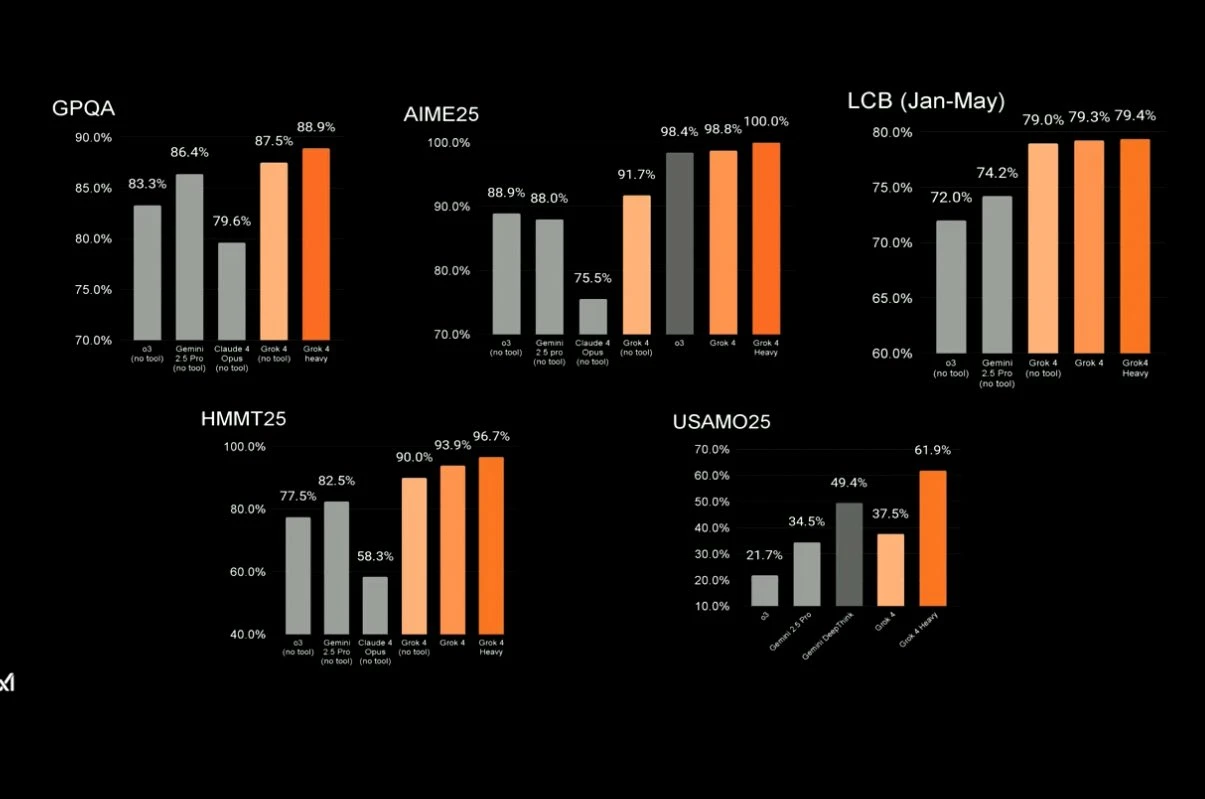
The model is rumored to be around 2.4 trillion params, and has the exact same pricing as Claude Sonnet, at $3 per million input tokens and $15 per million output tokens.
Reka Flash 3.1
Speaking of o3-mini level open source models, the Reka AI team released an upgrade to their 20b param flash model, mainly improving its code abilities, making it on par with o3-mini and Qwen3 32B.
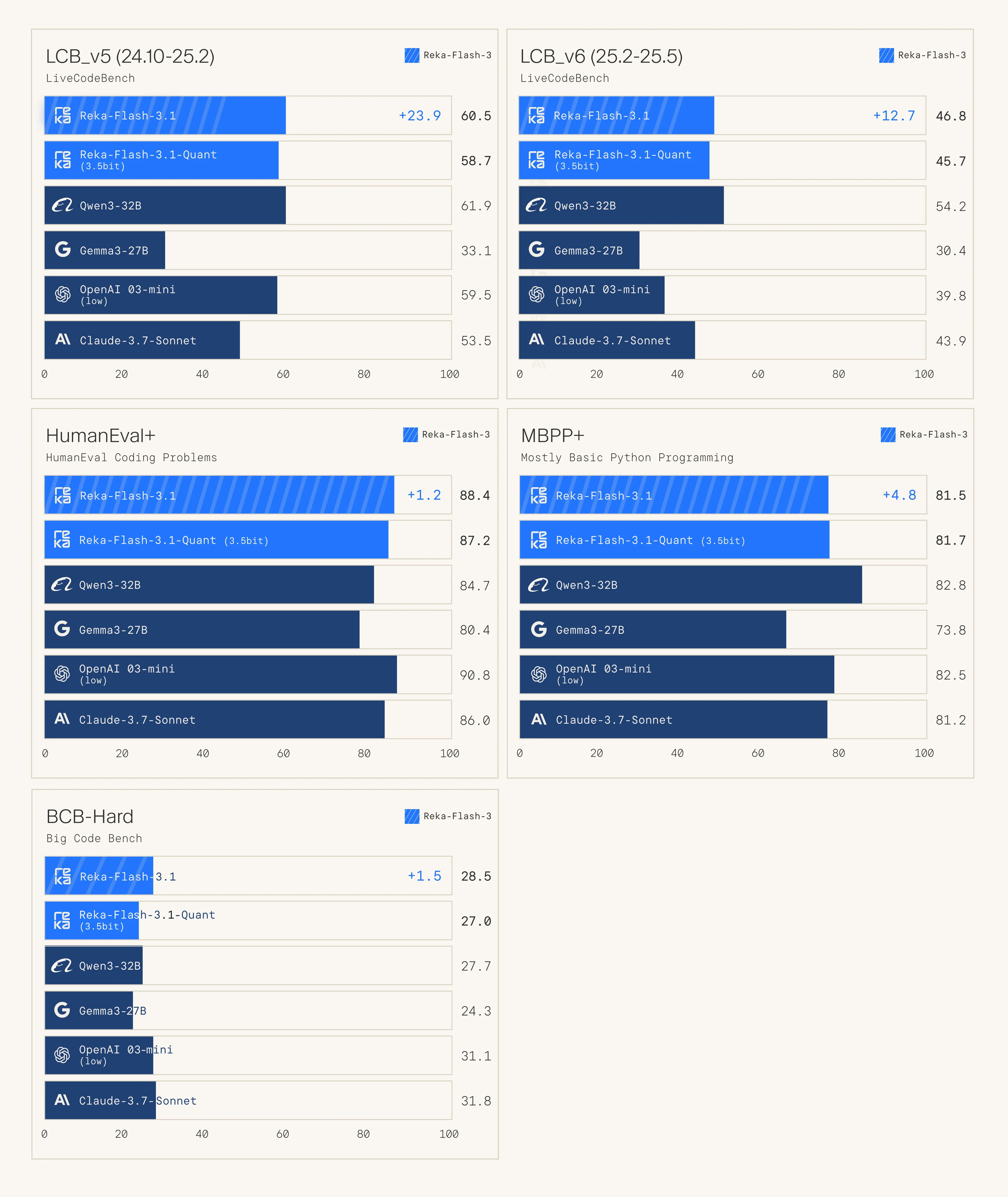
Reka has probably flown under the radar for most people, but they are a solid lab, similar to Mistral except American. Their flash series of models have been solid, similar in performance to Gemma3 27B and Mistral Small. It is multimodal as well, supporting both image and text inputs.
Research
Multiple Choice = bad eval
Some of the most common benchmarks that people use to evaluate model quality are multiple choice, for instance MMLU and GPQA. The issue with evaluating models like this is that we dont ask LLMs multiple choice questions in the real world. The format is meant to measure the knowledge that the LLMs have, but they might not even be doing that.
In a recent research paper from the Max Planck Institute, researchers show that LLMs are able to get the correct answer without ever seeing the question.
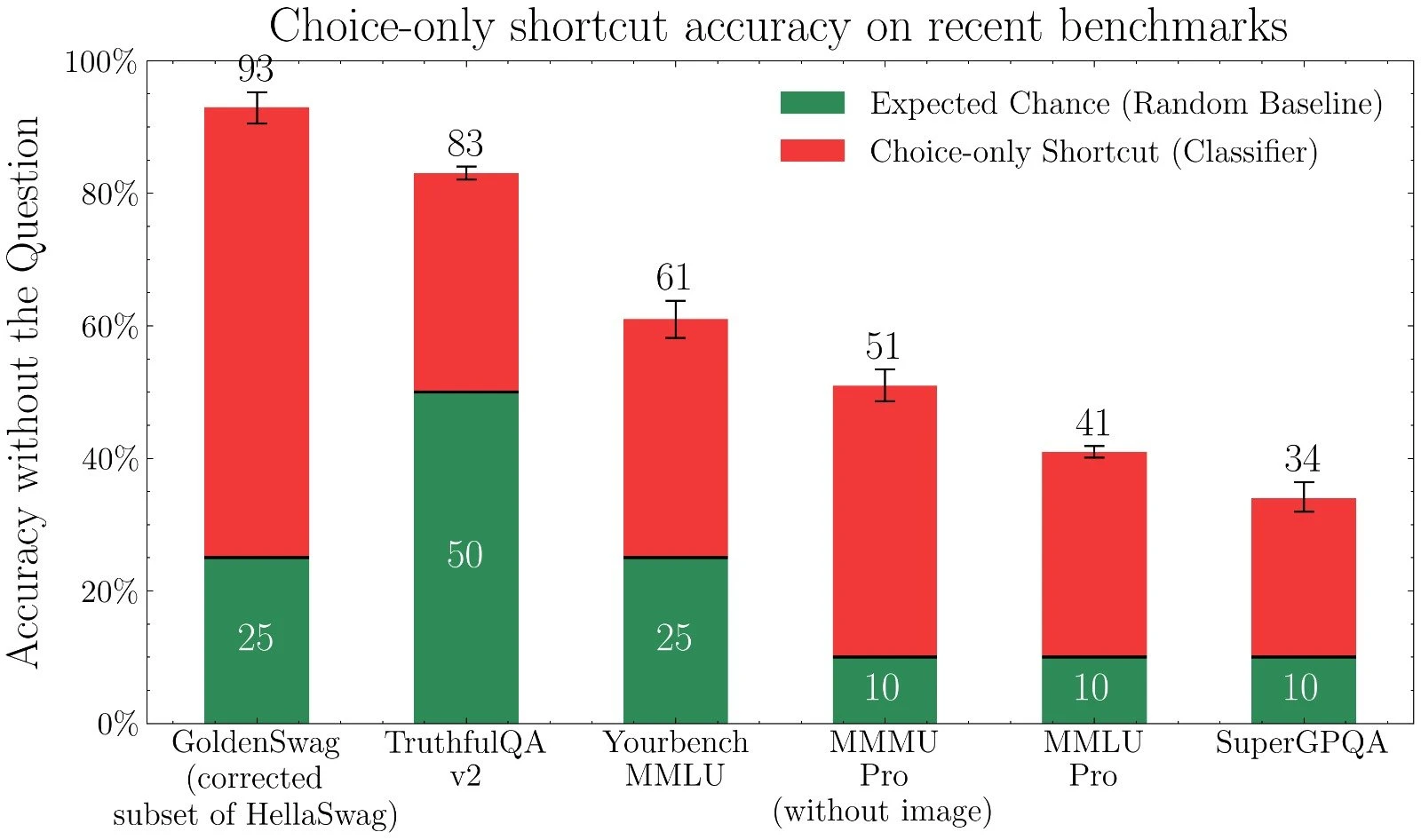
To remedy this issue, the researchers propose that the LLM is just given the question, and then use an LLM as a judge to verify if the answer is correct. The issue they come across however, is that it is harder to verify that an answer is correct than it is to generate a correct answer if no reference correct answer is provided.
This has big implications when running a question through an LLM multiple times and then having another LLM select the best answer (best of n sampling). It shows that we cannot reliably expect to find the correct answer from a set of potential answers.
The researchers overcome this issue with benchmarks by using answer matching (provide the LLM judge the reference answer) and have it see if the generated output matches the answer. But for open world LLM judges, the issue still exists.
Finish
I hope you enjoyed the news this week, if you want to get the news every week, be sure to join our mailing list below.